- Apriori
- An algorithm for extracting frequent itemsets with applications in association rule learning.
- The apriori algorithm has been designed to operate on databases containing transactions, such as purchases by customers of a store.
- An itemset is considered as "frequent" if it meets a user-specified support threshold. For instance, if the support threshold is set to 0.5 (50%), a frequent itemset is defined as a set of items that occur together in at least 50% of all transactions in the database.
Support
How often the product is purchased. range: [0,1]
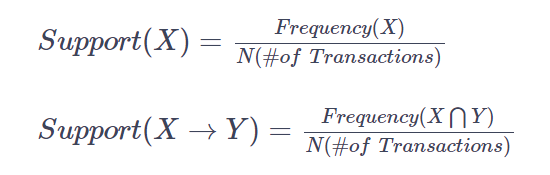
Confidence
How often items in Y appear in transactions that contain X. range: [0,1]

Lift
How likely item Y is bought together with item X, refers to the increase in the ratio of sale of B when A is sold.
When lift > 1 then the rule is better at predicting the result than guessing.
When lift < 1, the rule is doing worse than informed guessing. If X and Y are independent, the Lift score will be exactly 1. range: [0,∞]

apriori(df, min_support=, use_colnames=, max_len=)
import pandas as pd
import numpy as np
import sklearn
from sklearn.decomposition import TruncatedSVD
columns=['user_id', 'item_id', 'rating', 'timestamp']
df=pd.read_csv('./u.data',sep='\t',names=columns)
columns=['item_id', 'movie title', 'release date', 'video release date', 'IMDb URL', 'unknown', 'Action', 'Adventure',
'Animation', 'Childrens', 'Comedy', 'Crime', 'Documentary', 'Drama', 'Fantasy', 'Film-Noir', 'Horror',
'Musical', 'Mystery', 'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']
movies=pd.read_csv('./u.item', sep='|', encoding='latin-1',names=columns)
movie_names=movies[['item_id','movie title']]
combined_movies_data=pd.merge(df, movie_names, on='item_id')
combined_movies_data=combined_movies_data[['user_id','movie title']]
onehot=combined_movies_data.pivot_table(index='user_id',columns='movie title',aggfunc=len, fill_value=0)
onehot=onehot>0
from mlxtend.frequent_patterns import association_rules, apriori
frequent_itemsets=apriori(onehot, min_support=0.001, max_len=2, use_colnames=True)
rules=association_rules(frequent_itemsets)
rules_10=rules[:10]
rules[rules.antecedents.apply(str).str.contains('101 Dalmatians')].sort_values(by=['lift'], ascending=False)
>>>
antecedents consequents antecedent support consequent support support confidence lift leverage conviction
75 (101 Dalmatians (1996)) (Independence Day (ID4) (1996)) 0.115589 0.454931 0.098621 0.853211 1.875473 0.046037 3.713282
96 (101 Dalmatians (1996)) (Toy Story (1995)) 0.115589 0.479321 0.099682 0.862385 1.799180 0.044278 3.783598
...
pivot=rules_10.pivot(index='antecedents',columns='consequents',values='support')
sns.heatmap(pivot,annot=True)min_support : float (default: 0.5), A float between 0 and 1. Frequency, that is I want to consider only these guys that occurs over this number(how often item occurs). The support is computed as the fraction transactions_where_item(s)_occur / total_transactions.
max_len : int, Maximum length of the itemsets generated
use_colnames : bool (default: False), If true, uses the DataFrames' column names in the returned DataFrame instead of column indices.

reference : https://medium.com/swlh/a-tutorial-about-market-basket-analysis-in-python-predictive-hacks-497dc6e06b27
https://predictivehacks.com/item-based-collaborative-filtering-in-python/
'Analyze Data > Python' 카테고리의 다른 글
| FP-Growth (0) | 2021.07.01 |
|---|