- Json
JavaScript Object Notation, a format for exchanging structured data as text between clients and servers and vice versa. It came from JavaScript.
- Logstash
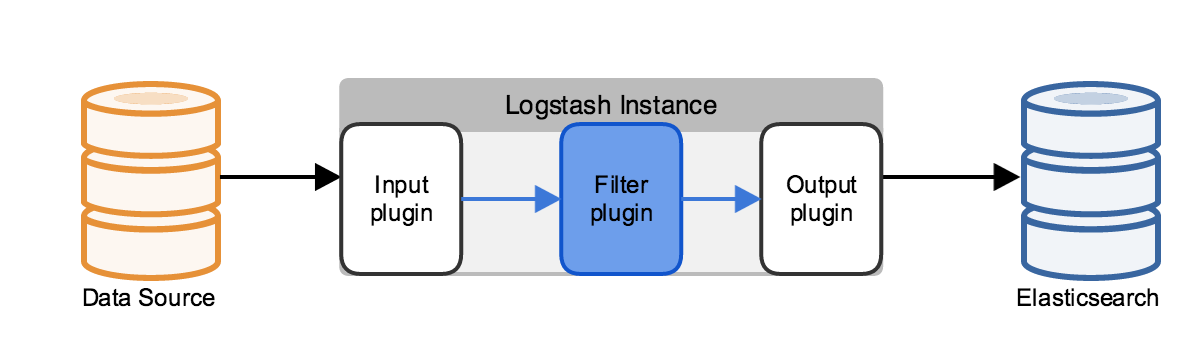
It is an open source data collection engine with real-time pipelining capabilities. It includes a Json filter plug-in as part of its default. The plug-in parses Json data and creates corresponding data structure in logstash event. Without this parsing step, the Json data would be ingested into Elasticsearch as a single line of text.
|
Log data --> Parsing --> Elasticsearch ⇡ Using the logstash JSON filter |
# sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
# sudo yum install logstash
...
Installed:
logstash.x86_64 1:7.12.0-1
Complete!reference : www.elastic.co/guide/en/logstash/7.12/installing-logstash.html
- Get, Configure, Run, Modify the data
1. Prepare data
Data(named sample-json.log) that represents a log of customer transactions that would be generated by a payment.
# wget http://media.sundog-soft.com/es/sample-json.log
--2021-04-15 21:53:20-- http://media.sundog-soft.com/es/sample-json.log
Resolving media.sundog-soft.com (media.sundog-soft.com)... 52.217.131.193
...
# cat sample-json.log
{"id":1,"timestamp":"2019-09-12T13:43:42Z","paymentType":"Amex","name":"Merrill Duffield","gender":"Female","ip_address":"132.150.218.21","purpose":"Toys","country":"United Arab Emirates","age":33}
...
cat : Concatenate, reads files sequentially, writing them to standard output. Takes a quick look at the data.
2. Configure logstash
Now, I am ready to configure logstash, spark up a new logstash configuration file by seeding into the logstash configuration directory.
[root@localhost yum.repos.d]# sudo nano json-read.conf
input { #use the file plug in
file { # input type is file
start_position => "beginning"
path => "/home/json-data/sample-json.log" #file path to here
sincedb_path => "/dev/null"
}
}
filter {
json{ #json data will be pulled in message field
source => "message" #It would parse the json from the message field.
}
}
output {
elasticsearch { #point to elasticsearch instance
hosts => "http://localhost:9200"
index => "demo-json"
}
stdout {} #for viewing the logs while running logstash
}reference : pcu-consortium.github.io/news/2017/Introduction-to-Logstash/
start_position : Where I want to read this file, it applies when file has read first time only. Default is end.
sincedb_path : Since Database Path, it let you set the path of the sincedb file that save which file you have already read and to where. So if your file has been updated, the modification are taken into account by logstash. It used to store offset file, meaning when restart logstash, it starts from offset.
- /dev/null : It is always empty folder, non-existent path in order to force it to parse the json file from the first line. Data will be eliminated once data transmitted to here. Doens't store offset, read file everytime.
source : A required setting, string, no default value for it.
- source => "message" : Every event will be stored in a field called a message by logstash.
stdout : Standard Output, is the default file descriptor where a process can write output.
3. Run it.
# sudo /usr/share/logstash/bin/logstash -f /etc/yum.repos.d/json-read.conf
...
{
"@timestamp" => 2021-04-16T03:16:16.224Z,
"age" => 34,
"country" => "Indonesia",
"message" => "{\"id\":4,\"timestamp\":\"2020-02-29T12:41:59Z\",\"paymentType\":\"Mastercard\",\"name\":\"Regan Stockman\",\"gender\":\"Male\",\"ip_address\":\"139.224.15.154\",\"purpose\":\"Home\",\"country\":\"Indonesia\",\"age\":34}",
"path" => "/home/json-data/sample-json.log",
"ip_address" => "139.224.15.154",
"timestamp" => "2020-02-29T12:41:59Z",
"purpose" => "Home",
"gender" => "Male",
"id" => 4,
"name" => "Regan Stockman",
"paymentType" => "Mastercard",
"host" => "localhost.localdomain",
"@version" => "1"
}
...
4. Let's check that data was inserted with the following curl request.
# curl localhost:9200/demo-json/_search?pretty=true
>>>
{
"took" : 14,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "demo-json",
"_type" : "_doc",
"_id" : "J_St2HgBNlJgER1w3oyY",
"_score" : 1.0,
"_source" : {
"@timestamp" : "2021-04-16T03:16:16.224Z",
"age" : 34,
"country" : "Indonesia",
..._search : Returns search hits that match the query defined in the request.
?pretty=true : JSON returned will be pretty formatted.
5. Clean up unnecessary fields
Now, I can remove these metadata fields by modifying the filter section. Because I don't want to index documents that contain the payment type filled with the value Mastercard. I want to remove unwanted metadata field.
# cp json-read.conf json-drop.conf #copy and change the name
# nano json-drop.conf #let's edit that new file
input {
file {
start_position => "beginning"
path => "/home/json-data/sample-json.log"
sincedb_path => "/dev/null"
}
}
filter {
json{
source => "message"
}
if [paymentType] == "Mastercard" {
drop {}
}
mutate {
remove_field => ["message", "@timestamp", "path", "host", "@version"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "demo-json-drop" #let's change the index name
}
stdout {}
}drop : it checks for events with paymentType and "Mastercard", if the condition matches, the event to be excluded from indexing by using the drop filter
remove_field : remove metadata fields that I don't want to bother
6. Run it.
# sudo /usr/share/logstash/bin/logstash -f /etc/yum.repos.d/json-drop.conf
>>>
...
{
"ip_address" => "132.150.218.21",
"timestamp" => "2019-09-12T13:43:42Z",
"country" => "United Arab Emirates",
"gender" => "Female",
"purpose" => "Toys",
"paymentType" => "Amex",
"age" => 33,
"id" => 1,
"name" => "Merrill Duffield"
} #There is no documents with the value Mastercard as I specified
...
# curl localhost:9200/demo-json-drop/_search?pretty=true
...
{
"_index" : "demo-json-drop",
"_type" : "_doc",
"_id" : "K_S62HgBNlJgER1wSIyC",
"_score" : 1.0,
"_source" : {
"ip_address" : "132.150.218.21",
"timestamp" : "2019-09-12T13:43:42Z",
"country" : "United Arab Emirates",
"gender" : "Female",
"purpose" : "Toys",
"paymentType" : "Amex",
"age" : 33,
"id" : 1,
"name" : "Merrill Duffield"
}
},
...
- Get, Configure, Run, Split the data
1. When I encounter arrays of objects, and I want to split that array into generating individual documents instead. Let's check it out with new data.
# wget http://media.sundog-soft.com/es/sample-json-split.log
# cat sample-json-split.log #I can see past events array can contain multiple transaction IDs
>>>
{"id":1,"timestamp":"2019-06-19T23:04:47Z","paymentType":"Mastercard","name":"Ardis Shimuk","gender":"Female","ip_address":"91.33.132.38","purpose":"Home","country":"France","pastEvents":[{"eventId":1,"transactionId":"trx14224"},{"eventId":2,"transactionId":"trx23424"}],"age":34}
...
[root@localhost yum.repos.d]# nano json-split.conf
input {
file {
#type => "json"
start_position => "beginning"
path => "/home/json-data/sample-json-split.log"
sincedb_path => "/dev/null"
}
}
filter {
json {
source => "message"
}
split {
field => "[pastEvents]"
}
mutate {
remove_field => ["message", "@timestamp", "path", "host", "@version"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "demo-json-split" #let's change the index name
}
stdout {}
}
split : It clones an event by splitting one of its fields and placing each value resulting from the split into a clone of the original event, so the array pastEvents will be split into corresponding object, the parent event or documents is then copied N times where N is the number of objects in the array.
2. Run it.
# /usr/share/logstash/bin/logstash -f /etc/yum.repos.d/json-split.conf
>>>
{
"age" => 34,
"gender" => "Female",
"timestamp" => "2019-06-19T23:04:47Z",
"ip_address" => "91.33.132.38",
"name" => "Ardis Shimuk",
"id" => 1,
"purpose" => "Home",
"pastEvents" => {
"eventId" => 1,
"transactionId" => "trx14224"
},
"country" => "France",
"paymentType" => "Mastercard" #each document was split into there's no more than one transaction ID and event ID for pastEvents that was passed in as part of that array
}
...
# curl -XGET "http://localhost:9200/demo-json-split/_search?pretty=true"
>>>
...
{
"_index" : "demo-json-split",
"_type" : "_doc",
"_id" : "M_RP2XgBNlJgER1wroxy",
"_score" : 1.0,
"_source" : {
"age" : 34,
"gender" : "Female",
"timestamp" : "2019-06-19T23:04:47Z",
"ip_address" : "91.33.132.38",
"name" : "Ardis Shimuk",
"id" : 1,
"purpose" : "Home",
"pastEvents" : {
"eventId" : 1,
"transactionId" : "trx14224"
},
"country" : "France",
"paymentType" : "Mastercard"
}
},
...
3. Clean up unnecessary fields.
# cp json-split.conf json-split-structured.conf
>>>
input {
file {
#type => "json"
start_position => "beginning"
path => "/home/json-data/sample-json-split.log"
sincedb_path => "/dev/null"
}
}
filter {
json {
source => "message"
}
split {
field => "[pastEvents]"
}
mutate {
add_field => {#Added "eventID", "transactionId" to the root of the document
"eventId" => "%{[pastEvents][eventId]}" #"eventID" map to
"transactionId" => "%{[[pastEvents][transactionId]}"
}
remove_field => ["message", "@timestamp", "path", "host", "@version"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "demo-json-split-structured" #let's change the index name
}
stdout {}
}add_field : Add any arbitrary fields to this event. Field names can be dynamic and include parts of the event using the %{field}.
4. Run it to examine more formally.
# /usr/share/logstash/bin/logstash -f /etc/yum.repos.d/json-split-structured.conf
>>>
{ #the structure has changed
"paymentType" => "Mastercard",
"gender" => "Female",
"path" => "/home/json-data/sample-json-split.log",
"id" => 1,
"age" => 34,
"timestamp" => "2019-06-19T23:04:47Z",
"purpose" => "Home",
"eventID" => "1",
"eventId" => 1,
"transactionId" => "trx14224"
"name" => "Ardis Shimuk",
"country" => "France",
"@timestamp" => 2021-04-16T06:37:12.089Z,
"ip_address" => "91.33.132.38",
}
...
# curl -XGET "http://localhost:9200/demo-json-split-structured/_search?pretty=true"
>>>
...
"_source" : {
"paymentType" : "Visa",
"message" : "{\"id\":4,\"timestamp\":\"2019-06-10T18:01:32Z\",\"paymentType\":\"Visa\",\"name\":\"Cary Boyes\",\"gender\":\"Male\",\"ip_address\":\"223.113.73.232\",\"purpose\":\"Grocery\",\"country\":\"Pakistan\",\"pastEvents\":[{\"eventId\":7,\"transactionId\":\"63941-950\"},{\"eventId\":8,\"transactionId\":\"55926-0011\"}],\"age\":46}",
"gender" : "Male",
...reference : www.youtube.com/watch?v=_qgS1m6NTIE