- Step
1. Devide the sentences into words.
2. Vectorize each words.
3. Set up the batch size.
Let's say here is data.
[[나는 사과를 좋아해], [나는 바나나를 좋아해], [나는 사과를 싫어해], [나는 바나나를 싫어해]]
1. Devide the sentences into words.
[['나는', '사과를', '좋아해'], ['나는', '바나나를', '좋아해'], ['나는', '사과를', '싫어해'], ['나는', '바나나를', '싫어해']]
2. Vectorize each words.
'나는' = [0.1, 0.2, 0.9]
'사과를' = [0.3, 0.5, 0.1]
'바나나를' = [0.3, 0.5, 0.2]
'좋아해' = [0.7, 0.6, 0.5]
'싫어해' = [0.5, 0.6, 0.7]↓
[[[0.1, 0.2, 0.9], [0.3, 0.5, 0.1], [0.7, 0.6, 0.5]],
[[0.1, 0.2, 0.9], [0.3, 0.5, 0.2], [0.7, 0.6, 0.5]],
[[0.1, 0.2, 0.9], [0.3, 0.5, 0.1], [0.5, 0.6, 0.7]],
[[0.1, 0.2, 0.9], [0.3, 0.5, 0.2], [0.5, 0.6, 0.7]]]
3. Let's say, set the batch size as 2.
첫번째 배치 #1
[[[0.1, 0.2, 0.9], [0.3, 0.5, 0.1], [0.7, 0.6, 0.5]],
[[0.1, 0.2, 0.9], [0.3, 0.5, 0.2], [0.7, 0.6, 0.5]]]
두번째 배치 #2
[[[0.1, 0.2, 0.9], [0.3, 0.5, 0.1], [0.5, 0.6, 0.7]],
[[0.1, 0.2, 0.9], [0.3, 0.5, 0.2], [0.5, 0.6, 0.7]]]
4. Let's say, imagine it. The size of tensor is 2*3*3 (batch size, length of sentence, vector dimention)
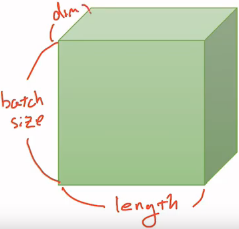
vector dimension, [0.1, 0.2, 0.9] is 3.
'Machine Learning' 카테고리의 다른 글
| model.parameters (0) | 2023.01.17 |
|---|---|
| Supervised vs Unsupervised Learning (0) | 2022.12.12 |
| tensorflow (0) | 2022.03.16 |
| Glance ML (0) | 2022.03.11 |
| Entropy, Cross-Entropy (0) | 2021.03.31 |