The idea behind the attention mechanism is that the decoder refer to entire input statement of encoder at every steps.
It will focus on the word(from encoder) which has more related to the word(decoder) to be predicted.
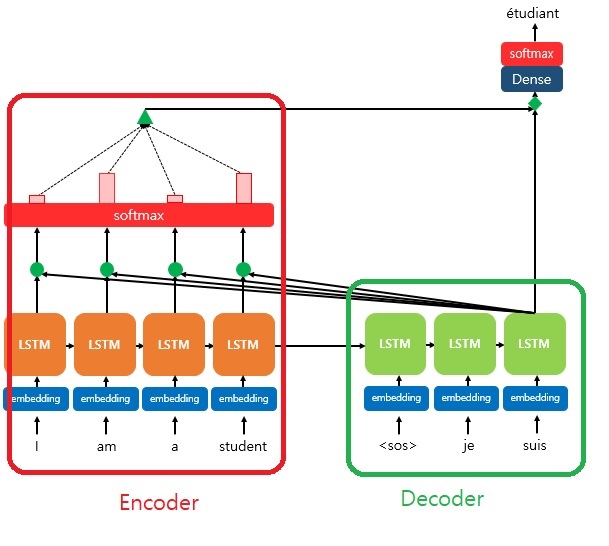
The result from the Softmax helps when Decoder predict the output word. The size of red rectangle represents how it helps to predict. The larger the rectangle, more helpful to predict. When each input word is quantified, it is sent to the Decoder as a single piece of informaton(the green triangle). As a result, the Decoder has a higher probability of predicting the output word more accurately.
Steps
1. Attention Score
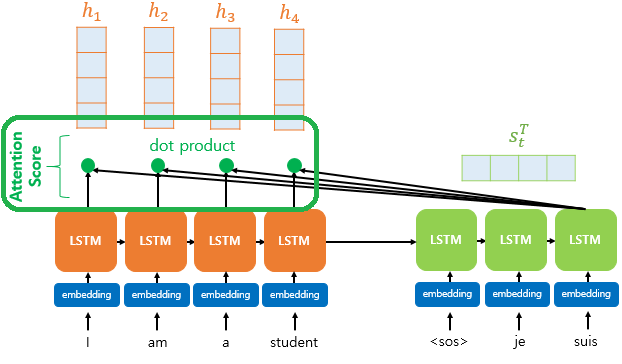
In order to get the attention value, it need to be get first.
It presents how much resemble between each of the Encoder's hidden states and the Decoder's hidden state at this point(st).
2. Attention Distribution
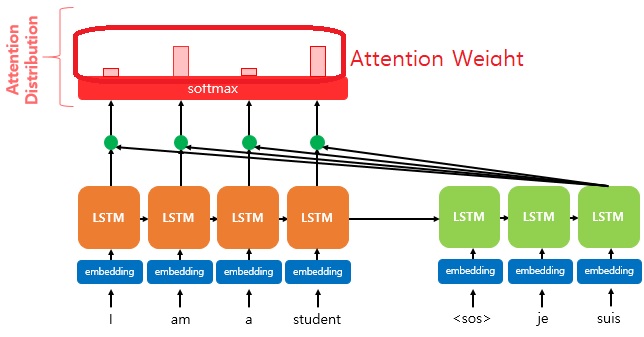
The result which is obtained by applying the attention score for all time points of the Encoder to Softmax(between 0 and 1). It obtained 'The probability distribution'.
3. Attention Weight
Respective value of Attention Distribution.
4. Attention Value
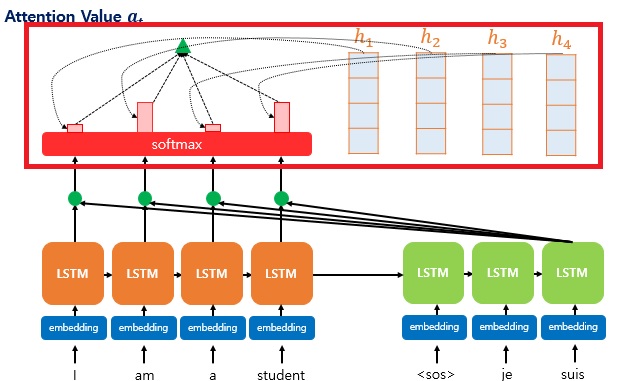
The value after multiply each Encoder's hidden state and Attention Weight, and finally add them all.
It is also called the Context Vector as it contains the context of the Encoder.
5. Concatenate

Make a Vector after concatenate Attention Value on the Decoder's hidden state at this point(st).
6. Hyperbolic tangent function

After Concatenate, multiply by the weiht matrix, pass through the Hyperbolic Tangent Function to obtain a new Vector.
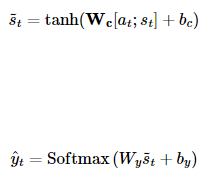
y ̂ is the final Vector.
'Deep Learning' 카테고리의 다른 글
| 2. Fundamentals of CNNs and RNNs (0) | 2023.01.31 |
|---|---|
| 1. Fundamentals of CNNs and RNNs (0) | 2023.01.31 |
| AutoEncoder (0) | 2022.12.12 |
| encoding vs embedding (0) | 2022.12.08 |
| BPE(Byte Pair Encoding) (0) | 2022.11.30 |