- Loss function
In deep learning, we typically use a gradient-based optimization strategy to train a model
using some loss function
where
are some input-output pair. It is used to help the model determine how "wrong" it is and, based on that "wrongness," improve itself. It's a measure of error. Our goal throughout training is to minimize this error/loss.
- Gradient Descent
Reducing the value of the loss function.
| Gradient Descent by batch size | ||
| Gradient Descent | 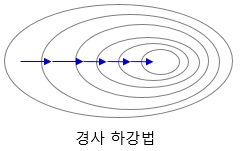 |
Training : all data → : by epochs |
| Stochastic Gradient Descent(SGD) | 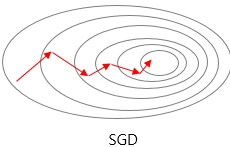 |
Training : random data → : by batch |
| Mini-batch Gradient Descent | 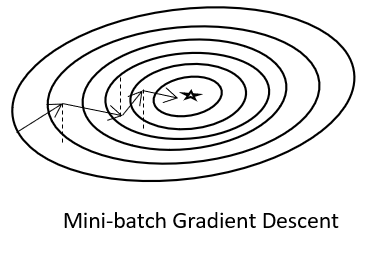 |
Training : designated data → : by batch |
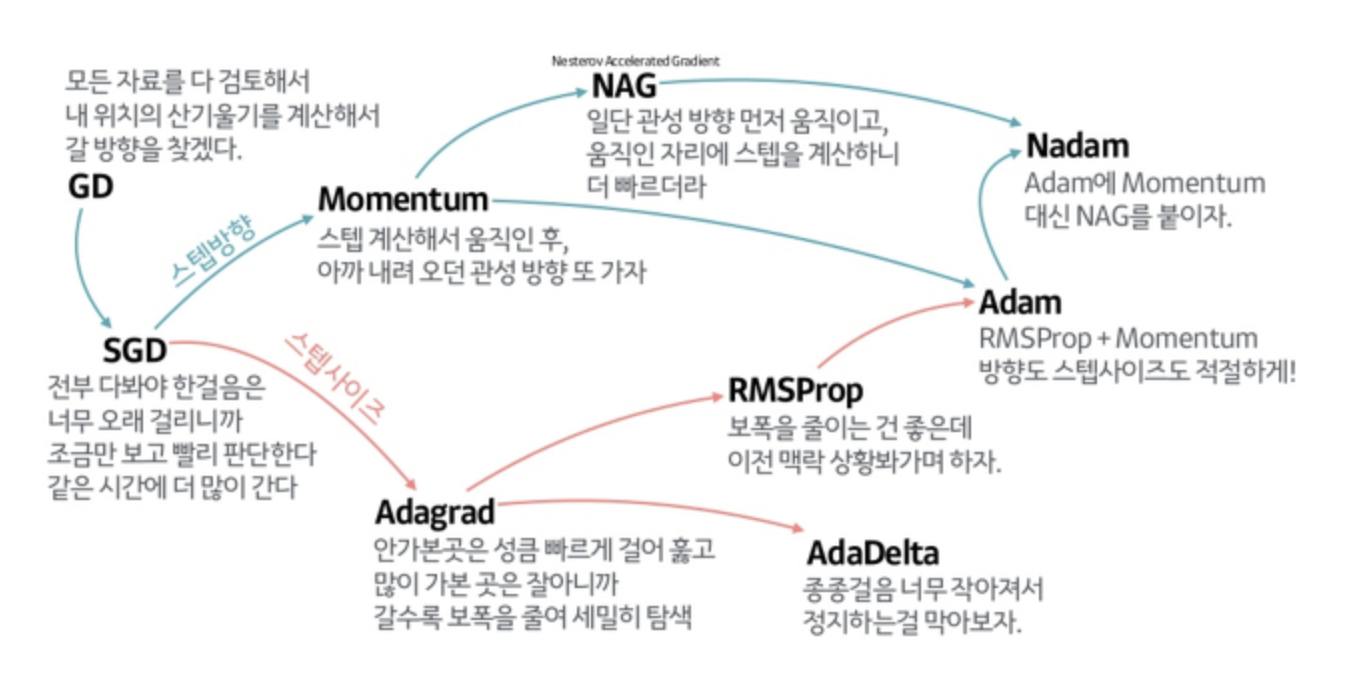
- optimizer
| Optimizer | ||
| Momentum |  |
|
| Adagrad | Parameters with many changes set a small learning rate, few changes set a high learning rate. |
|
| RMSprop | Improve Adagrad | |
| Adam | Combine RMSprop and momentum. | |
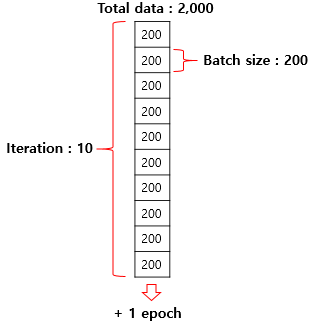
- Epochs
How many time train all data.
- Batch size
Data unit
Let's say one data size is 256. For instance, it consists of [3,1,2,5, ...] and length is 256.
In other words, one data size = vector dimension = 256
If number of data is 3,000, total data size is 3,000 * 256.
Computer processes the data in chunks rather than processing them one by one.
If you take out 64 pieces of 3,000, then the batch size is 64.
Therefore the computer processes at once is (batch size × dim) = 64 × 256
- One data
| [3,1,2,5, ...] length = 256 |
- Number of data
| [3,1,2,5, ...] length = 256 |
... 3,000
| [3,1,2,5, ...] length = 256 |
'Deep Learning' 카테고리의 다른 글
| Terms-text encoding, text decoding, embedding (0) | 2022.09.23 |
|---|---|
| Word2Vec (0) | 2022.03.29 |
| Activation function (0) | 2022.03.17 |
| sklearn (0) | 2022.03.08 |
| Dropout, Gradient Clipping, Weight Initialization, Xavier, He, Batch Normalization, Internal Covariate Shift, Layer Normalization (0) | 2021.04.08 |