- Keras
1. Preprocessing
from tensorflow.keras.preprocessing.text import Tokenizer
t=Tokenizer()
fit_text='The earth is an awesome place live'
t.fit_on_texts([fit_text])
test_text='The earth is an great place live'
sequences=t.texts_to_sequences([test_text])[0]
sequences
>>>[1, 2, 3, 4, 6, 7]
t.word_index
>>>{'an': 4, 'awesome': 5, 'earth': 2, 'is': 3, 'live': 7, 'place': 6, 'the': 1}Tokenizer.fit_on_texts() : It returns text to list. Updates internal vocabulary based on a list of texts. In the case where texts contains lists, we assume each entry of the lists to be a token.
Tokenizer.texts_to_sequences() : Transforms each text in texts to a sequence of integers. The most frequent words will be taken into account.
from tensorflow.keras.preprocessing.sequence import pad_sequences
pad_sequences([[1,2,3],[3,4,5,6],[7,8]],maxlen=3, padding='pre')
>>>
array([[1, 2, 3],
[4, 5, 6],
[0, 7, 8]], dtype=int32)pad_sequences() : pads sequences to the same length.
- maxlen= : Maximum length of all sequences.
- padding= : 'pre' or 'post', pad either before or after each wequence. If 'pre', pad 0 before, otherwise, pad 0 later
2. One-hot encoding
Transform words to one-hot vector
i.g. one-hot vector : sparse vector, it has only one 1 value, rest of them are 0. i.g. [0 1 0 0 0 0 ... 0 0 0 0 0 0 0]
3. Word Embedding
Transform words to dense vector
i.g. dense vector : embedding vector, all float. i.g. [0.1 -1.2 0.8 0.2 1.8]
Embedding(number of samples, input_length) : 2-D integer tensor input
- number of samples : the result from integer encoding, in other words, it is integer sequence
↓
Imprementing Embedding
↓
Embedding(number of samples, input_length, embedding word dimensionality) : 3-D integer tensor output
text=[['Hope', 'to', 'see', 'you', 'soon'],['Nice', 'to', 'see', 'you', 'again']]
text=[[0, 1, 2, 3, 4],[5, 1, 2, 3, 6]]
Embedding(7, 2, input_length=5)7 words in total, 2 dimensions, length of sequence is 5
4. Modeling
- Sequential
- Using it in order to compose input layer-hidden layer-output layer.
- It lets stack the layers one by one.
- It connects several functions such as Wx+b, Sigmoid.
- model.add()
- adding the layer step by step
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
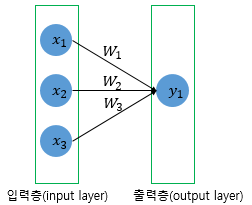
model.add(Dense(1, input_dim=3, activation='relu'))
1 is number of output neurons, input_dim is number of input neurons, 'relu' is activation function(linear, sigmoid, softmax, relu)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(8, input_dim=4, activation='relu'))
model.add(Dense(1, activation='sigmoid'))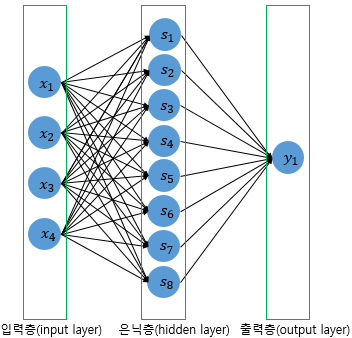
5. Compile
To set the model's loss function, optimizer, and metrics before training the model.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
'Deep Learning > Tensorflow' 카테고리의 다른 글
| GradientTape (0) | 2023.12.12 |
|---|---|
| reduce_sum, cast, argmax, image_dataset_from_directory, one_hot, reduce_mean, assign_sub, boolean_mask, random.normal, zeros (0) | 2023.12.12 |
| LSTM (0) | 2022.09.15 |
| keras-Tokenizer (0) | 2021.03.08 |
| gensim, Scikit-learn, NLTK, TreebankWordTokenizer, WordPunctTokenizer, sent_tokenize, pos_tag, word_tokenize, NLP, text_to_word_sequence, Corpus (0) | 2021.03.05 |