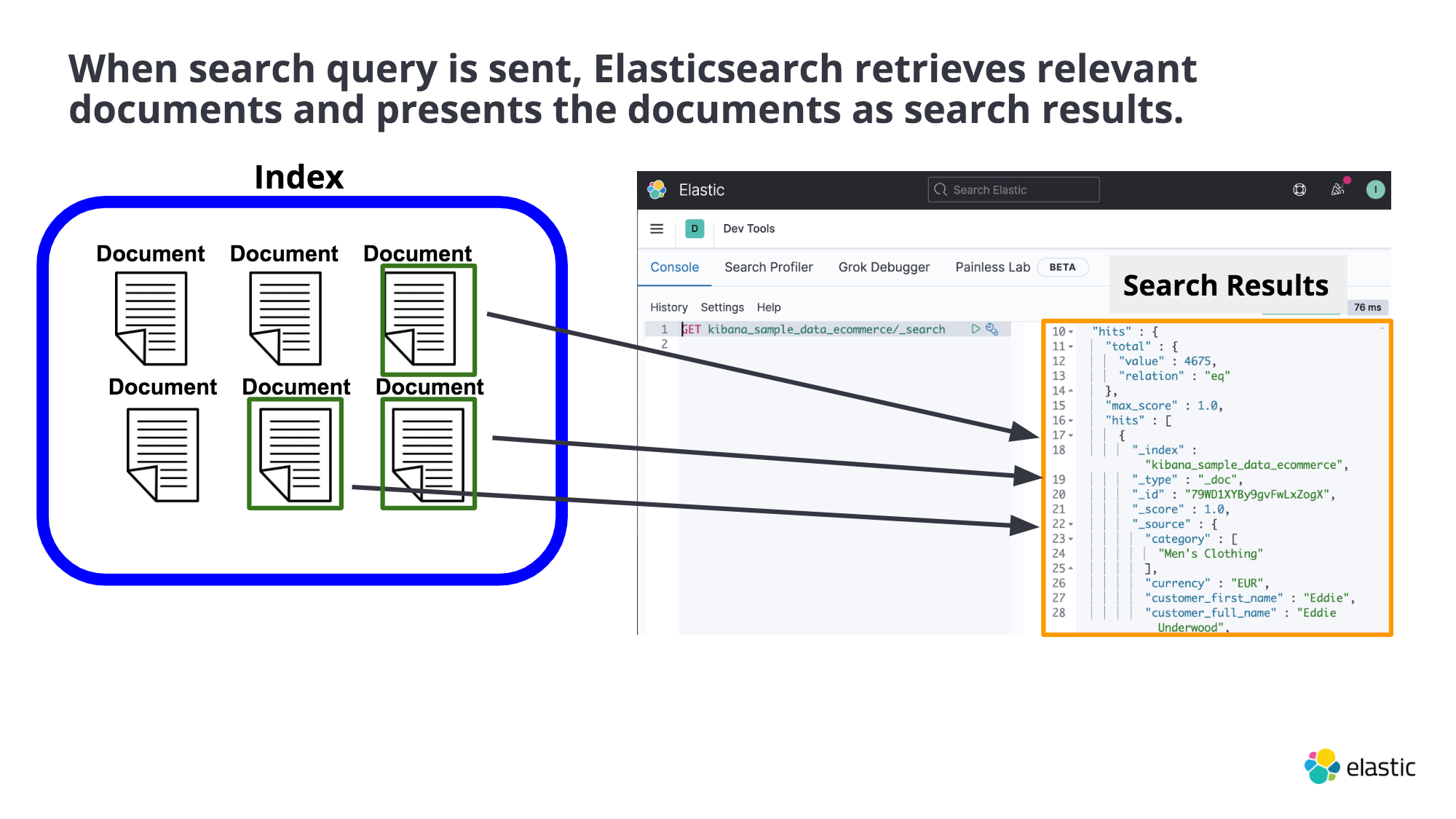
Document : Data is stored as document that share similar traits are grouped into an index.
User
↓ ⇢ search something
Elasticsearch
↓ ⇢ retrieves relevant documents, then Elasticsearch presents them as search results
Search Results
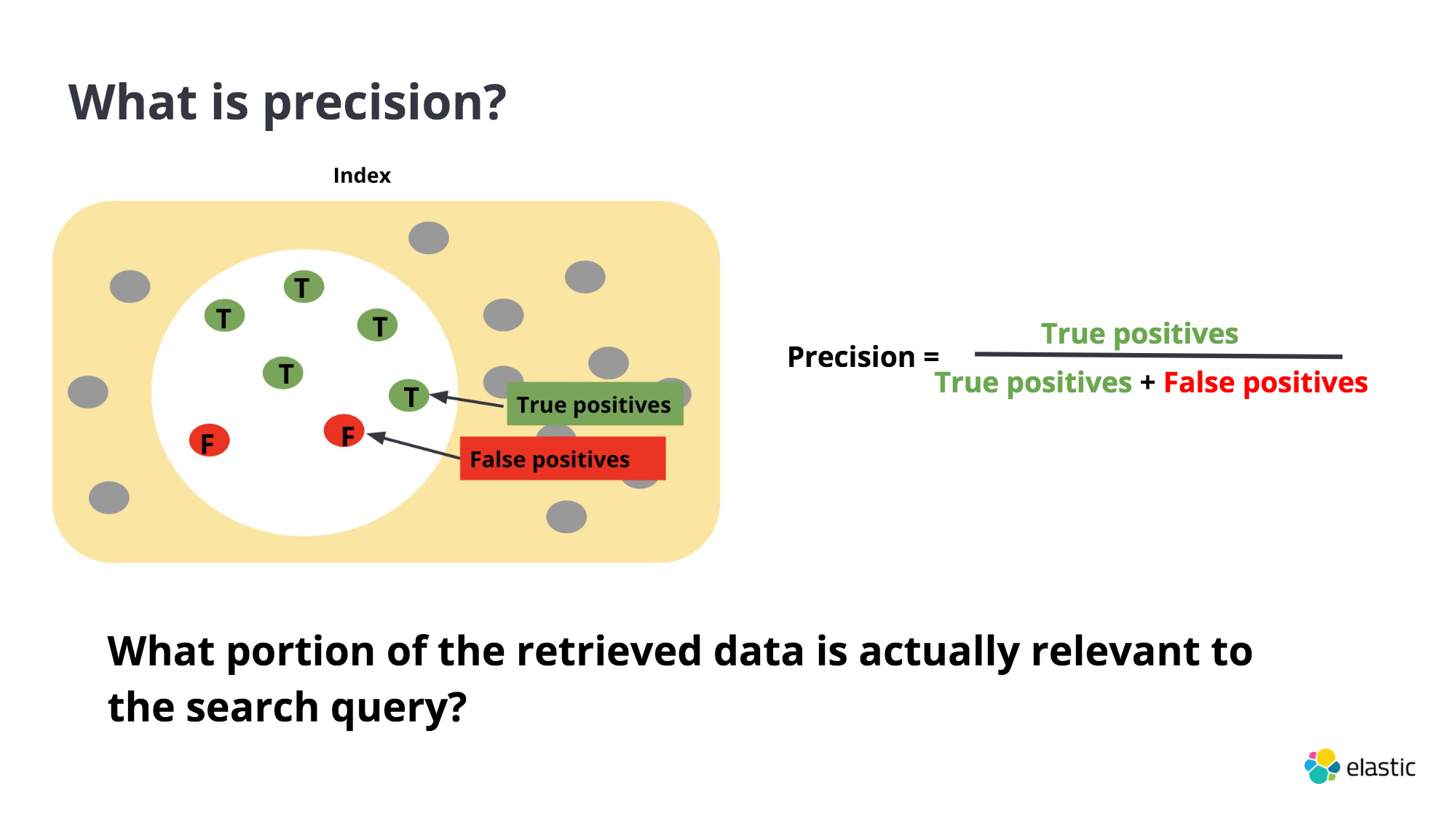
Precision : The dots inside the white circle, the portion of the retrived data actually relevant to the search query. All the retrived results to be a perfect match to the query, even if it means returning less documents.
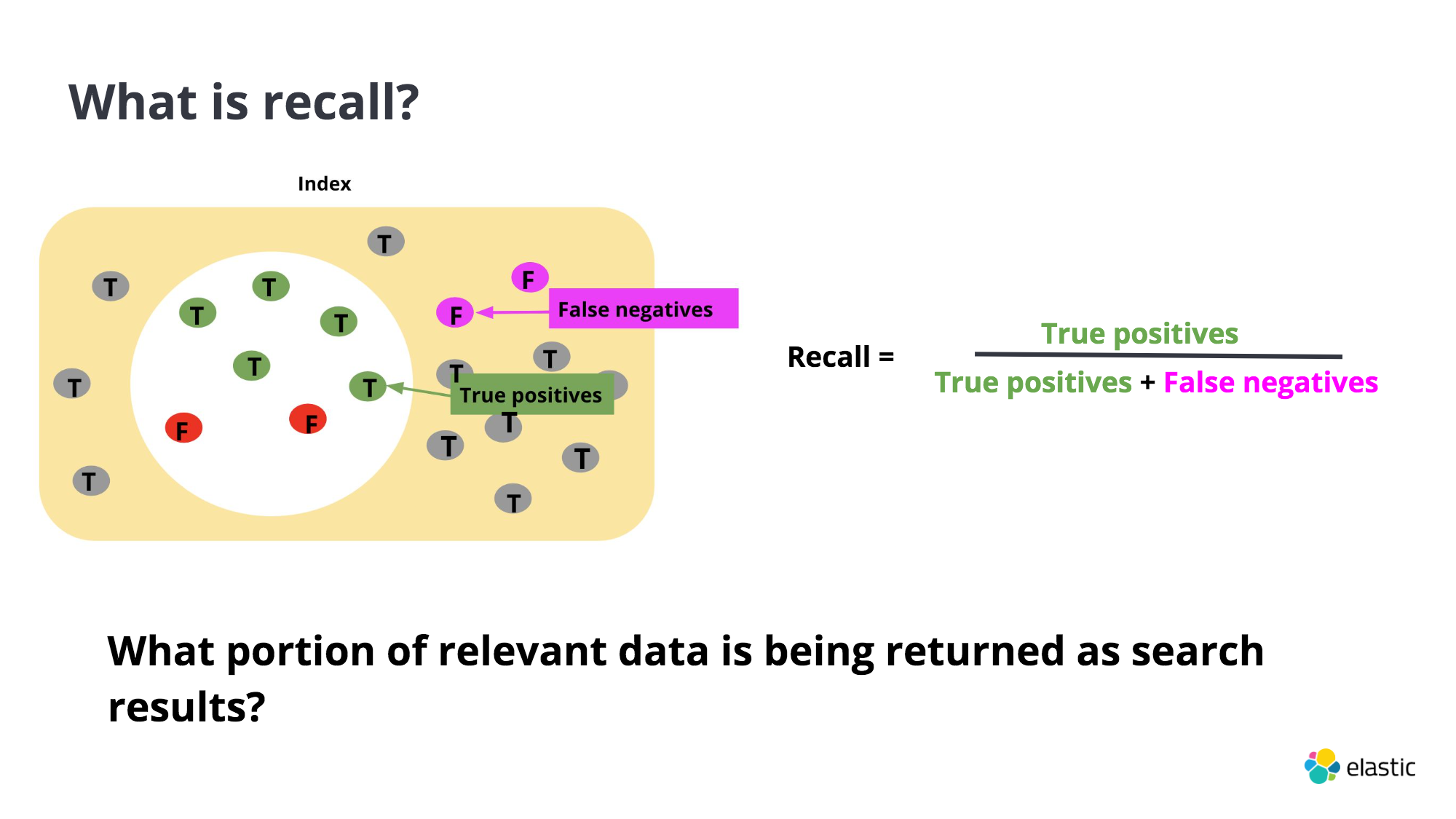
Recall : The portion of relevant data being returned. Return more results even if documents may not be a perfect match to the query.
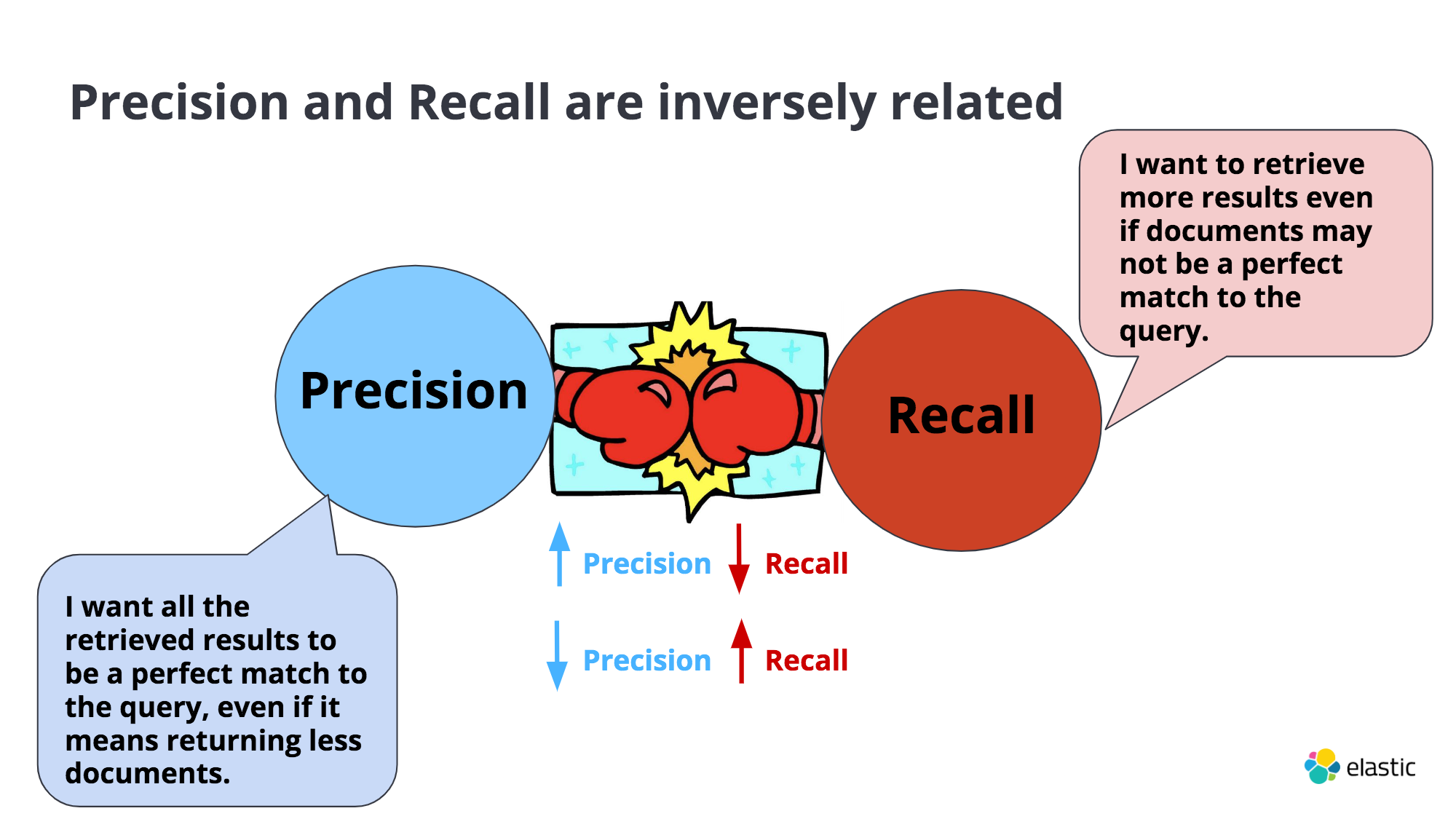

Precision and Recall determined by ranking. The most relevant results are at the top and the least relevant at the bottom. And the ranking or order is determined by a scoring.
Score : It is a value that represents how relevant a documents is to that specific query, is computed for each documents that is a hit.

Term Frequency(TF) : It determines how many times each search terms appears in a document. If search terms are found in high frequency in a document, the document is considered more relevant to the search query, assigns a higher score to that document.
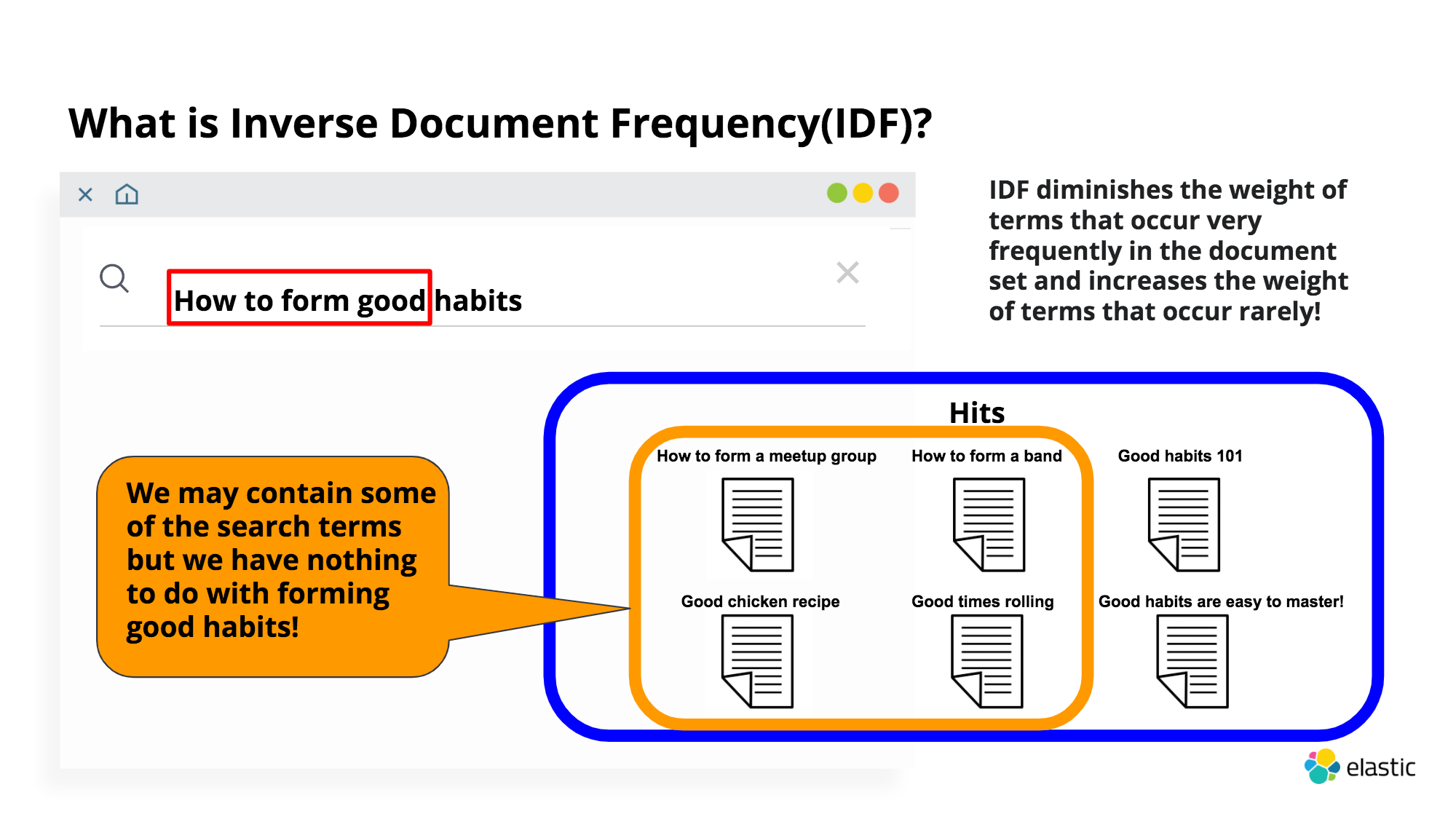
Inverse Document Frequency(IDF) : Even though there are irrelevant to the query with higher score, it offsets this. If certain search terms are found in many documents, it knows that these terms are not useful. So it reduces the score with unimportant search terms and increase the score for the documents with important search terms like habits(above pic).
GET news_headlines/_search
>>>
{
"took" : 5,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
...GET name_of_the_index_what_I_made/_search : get search result from the index, it returns information of all documents in the index
"hits" : It gives 10 sample results by default
_search : You can get general idea of what a document looks like
"value" : It tells you the total value of hits 10,000 by default
"relation"
- eq : Equal, meaning the value is equal to the total number of hits.
- gte : Greater Than Equal, meaning the number of hits is greater than or equal to 10,000
GET news_headlines/_search
{
"track_total_hits": true
}
>>>
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 200853,
"relation" : "eq"
},
..."track_total_hits": true : It returns the exact total number of hits, and we can see "relation" is "eq".
I want to find interesting patterns in the data, but it is hard so one way to narrow it down is search for data within a specific time range that you're interested in.
GET news_headlines/_search
{
"query": {
"range": {
"date": {
"gte": "2015-06-20",
"lte": "2015-09-22"
}
}
}
>>>
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 8388,
"relation" : "eq"
},
..."query" : It retrieves documents that match the criteria
GET news_headlines/_search #I want to get search results from news_headlines
{
"aggs": { #I am sending an aggregation request
"by_category": { #I want you to name this by_category
"terms": {
"field": "category",
"size": 100 #Bring me up to 100 categories
}
}
}
}
>>>
{
"took" : 37,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
...
"by_category" : { #I can access the aggregations that I named by_category
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
... "aggregation" : Get the summary of categories, If I want to know which type of news categories exist in my data,
I want to identify the most popular topics in an entertainment category, so let's make a combo of both query and aggregatons requests. It means first, I am going to pull all the documents from the entertainment category, then give the summary of the most significant topics in the entertainment category.
GET news_headlines/_search
{
"query": {
"match": { #All the documents that match the following criteria
"category": "ENTERTAINMENT" #The documents will be from category ENTERTAINMENT
}
},
"aggs": { #On the documents that I just queried
"popular_in_entertainment": { #I want to this to be named "popular_in_entertainment"
"significant_text": { #I want to run an analysis on the significant text
"field": "headline" #that is found in field headline
}
}
}
}
>>>
...
"aggregations" : { #I access to aggregations report
"popular_in_entertainment" : { #that is named "popular_in_entertainment"
"doc_count" : 16058,
"bg_count" : 200853,
"buckets" : [
{
"key" : "trailer",
"doc_count" : 387,
"score" : 0.21944632913239076,
"bg_count" : 479
},
...
GET news_headlines/_search
{
"query": { #Give me all the data
"match": { #that matches the following criteria
"headline": {
"query": "Khloe Kardashian Kendall Jenner" #Bring me all documents that contain these search terms in the headline field
}
}
}
}
>>>
...
"hits" : {
"total" : {
"value" : 926,
"relation" : "eq"
},
...It turned a lot of articles(926, recall) that mention these search terms but these are not perfect matches to the query. Because my search query containes four search terms-Khloe Kardashian Kendall Jenner. The match query uses an OR logic by default, so this query considered as a hit if it contains even one of these search terms in the headline.
In order to increasing precision, we can add AND operator. Inversely when I use OR by default, I got one as a result. This is perfect match so I definitely improved my precision.
GET news_headlines/_search
{
"query": {
"match": {
"headline": {
"query": "Khloe Kardashian Kendall Jenner",
"operator": "and"
}
}
}
}
>>>
...
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
..."operator": "and" : Only pull up documents that contain all four(above example) of these search terms.
With first query, it widened the net too much so it returns a lot of loosely related search results, but with second query, it was way too strict. Is there a way to land somewhere in between them?
GET news_headlines/_search
{
"query": {
"match": {
"headline": {
"query": "Khloe Kardashian Kendall Jenner",
"minimum_should_match": "3" #At least three search terms must be included in the headlines
}
}
}
}
>>>
...
"hits" : {
"total" : {
"value" : 6,
"relation" : "eq"
},
..."minimum_should_match" : It allows you to specify the minimum number of terms a document should have to be included in the search results. This parameter gives you more control over fine tuning precision and recall of your search.
Reference : www.youtube.com/watch?v=CCTgroOcyfM
'Elastic Stack > Elasticsearch' 카테고리의 다른 글
| Elasticsearch, Docker-compose, Python module (0) | 2021.12.09 |
|---|---|
| match, match_phrase, multi_match, Per-field boosting(^), "type": "phrase", bool (0) | 2021.04.15 |
| Structure of Elasticsearch, Node, Cluster, Document, Shard, Sharding, Primary shard, Replica shard (0) | 2021.04.14 |
| install elasticsearch on docker (0) | 2021.04.13 |