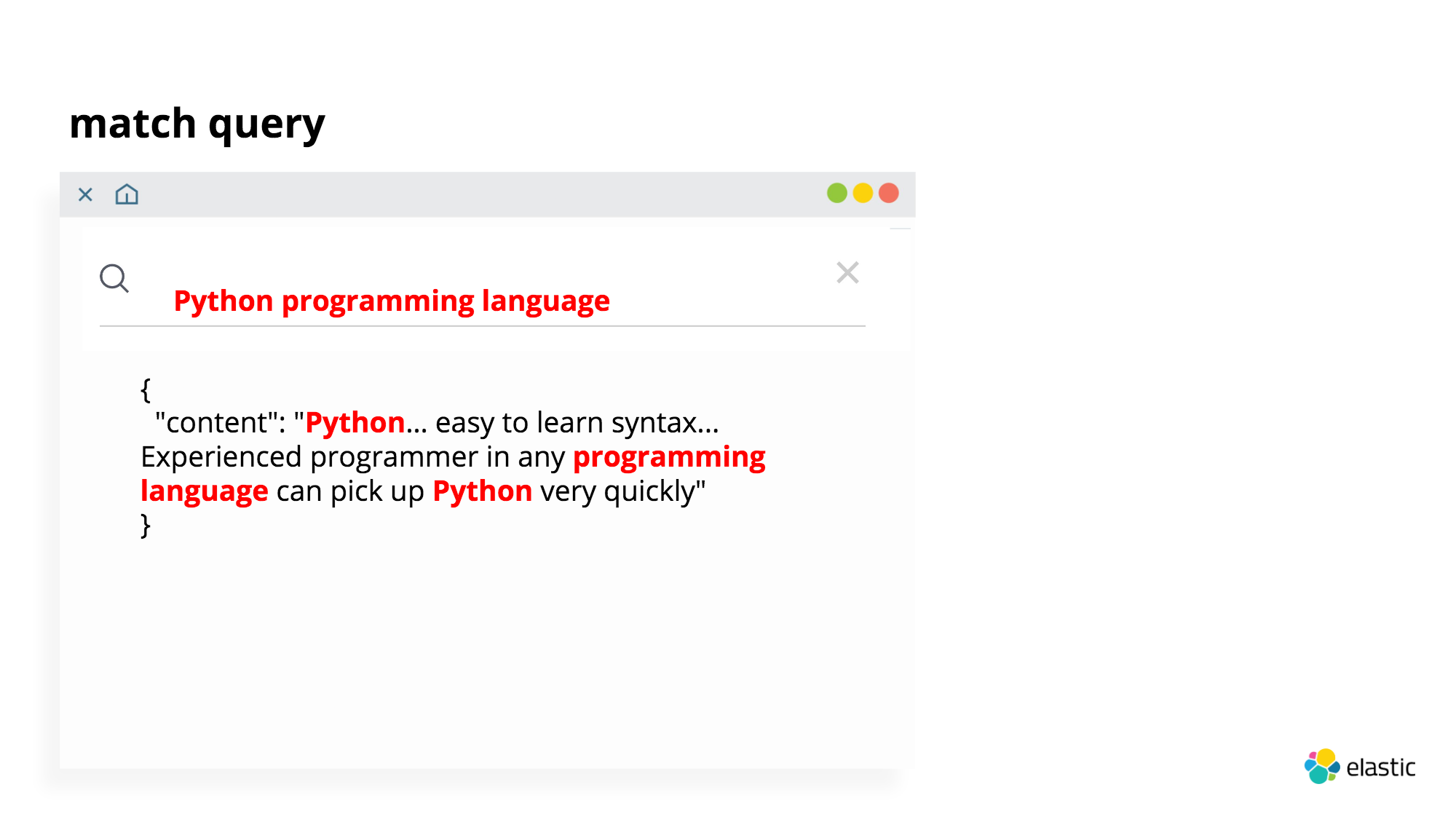
- match
It performs a full text search. Elasticsearch will look for these terms in the documents as long as all or one of these terms are found within the documents, and the match query will send these results back, it doesn't care about the order or the proximity. So it pulls up documents with search terms that are scatterd across the documents.
GET news_headlines/_search
{
"query": { #I want to query all documents
"match": { #that match the following criteria
"headline": { #that include these search terms(Shape of you) in the headline
"query": "Shape of you"
}
}
}
}
>>>
...
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : 12.274778,
...
- match_phrase
"Shape", "of", and "you" must appear in the headline field. And the terms must appear in that order, must appear next to each other.
"match_phrase" : {"A" : "B"} : It designed to search for phrases, match the following phrase. "B" is a phrase I am looking for, "A" is the field where the phrase should be found.
GET news_headlines/_search
{
"query": {
"match_phrase": {
"headline": {
"query": "Shape of you" #"Shape of you" must appear in the headline, must appear in that order, must appear next to each other.
}
}
}
}
>>>
...
"hits" : {
"total" : {
"value" : 3, #recall is a lot lower compared to 10,000 hits that I had before
"relation" : "eq"
},
...
"category" : "LATINO VOICES",
"headline" : "Ed Sheeran's 'Shape Of You' Gets An Unexpected Latin Remix" #It is very precise match
...
- multi_match
Multiple queries run on each field and calculates a score for each field(multiple fields) with OR logic by default(means anyone of these search terms appear in any of these fields). Then it assigns the highest score among the fields to the document. But top hits are not primarily about "Michelle Obama".
GET news_headlines/_search
{
"query": {
"multi_match": {
"query": "Michelle Obama",
"fields": [
"headline",
"short_description",
"authors"] #Find the search terms "Michelle" and "Obama" in the headline, short_description, and author fields
}
}
}
>>>
...
"hits" : {
"total" : {
"value" : 5128, #"Michelle Obama" in one or more fields that we specified
"relation" : "eq"
},
...
- Per-field boosting(^)
If "Michelle Obama" is mentioned in the headline instead of the short_description, it's highly likely that the article would be primarily about her. Let's carry more weight than the short_description. To improve the precision of your search, you can designate one field to carry more weight more than others. This can be done by boosting the score of the field headline using the carat(^) symbol.
GET news_headlines/_search
{
"query": {
"multi_match": {
"query": "Michelle Obama",
"fields": [
"headline^2","short_description","authors"]
}
}
}
>>>
...
"headline" : "Michelle Obama Appears On 'Jeopardy!'",
...
"headline" : "Michelle Obama To Appear On 'NCIS'",
...
The ranking of the heads have changed.
- "type": "phrase"
It performs a match_phrase query on each field and calculates a score for each field. Then it assigns the best score to the document. It only pulls up documents that contain the exact phrase.
GET news_headlines/_search
{
"query": {
"multi_match": {
"query": "party planning",
"fields": [
"headline^2","short_description"],
"type": "phrase"
}
}
}
>>>
...
"hits" : {
"total" : {
"value" : 6, #6 hits have the phrase "party planning" in either short_description or in the headline
"relation" : "eq"
},6 hits have the phrase "party planning" in either short_description or in the headline. The ones that contain the phrase in the headline are shown higher on the list.
- bool
1. "must" : It defines all the queries(criteria) a document MUST match to be returned as hits. As a result, it will increase the precision.
GET news_headlines/_search
{
"query": {
"bool": {
"must": [
{"match_phrase": {
"headline": "Michelle Obama" #It returns all headline have "Michelle Obama"
}},
{
"match": {
"category": "POLITICS" # "Michelle Obama" headline are categorized under "POLITICS"
}
}
]
}
}
}All documents will contain "Michelle Obama" in the headline field and "POLITICS" in the category field.
2. "must_not" : It defines queries(criteria) a document MUST NOT match to be included in the search results.
Now, I want to know non-political thing she has been up to but except for her wedding. I can use both MUST and MUST_NOT come in handy.
GET news_headlines/_search
{
"query": {
"bool": {
"must": {
"match_phrase": {
"headline": "Michelle Obama"
}
},
"must_not":[
{
"match": {
"category": "WEDDINGS" #It shows me all articles from all categories except for wedding
}
}
]
}
}
}
3. "should" : It is nice to have criteria, not having these qulities. The documents do not need to meet these criteria to be considered as hits however the ones that do will be given a higher score. It doesnt add or exclude more hits however it does change the ranking of the documents.
The hits do not have to match the queries however if there are matches the phrase "BLACK VOICES" in the category, then give it a higher score so it ends up higher in the search results.
GET news_headlines/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"headline": "Michelle Obama"
}
}
],
"should": [
{
"match_phrase": {
"category": "BLACK VOICES"
}
}
]
}
}
}
>>>
...
"hits" : {
"total" : {
"value" : 207, #Got the same number as previous query
"relation" : "eq"
},
...
4. "filter" : Places documents in either yes or no category. Ones that fall into the yes category are included in the hits. For example, let's say you are looking for an article written in certain time range. Some documents will fall within this range(yes) or do not fall within this range(no).
GET news_headlines/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"headline": "Michelle Obama"
}
}
],
"filter": [
{
"range": { #It determines which document fall within this range and which ones don't, only that fall into the yes category will be included in the hits
"date": {
"gte": "2014-03-25",
"lte": "2016-03-25"
}
}
}
]
}
}
}
Reference : www.youtube.com/watch?v=2KgJ6TQPIIA&t=132s
'Elastic Stack > Elasticsearch' 카테고리의 다른 글
| Elasticsearch, Docker-compose, Python module (0) | 2021.12.09 |
|---|---|
| Precision, Recall, Term Frequency, TF, Inverse Document Frequency, IDF (0) | 2021.04.15 |
| Structure of Elasticsearch, Node, Cluster, Document, Shard, Sharding, Primary shard, Replica shard (0) | 2021.04.14 |
| install elasticsearch on docker (0) | 2021.04.13 |