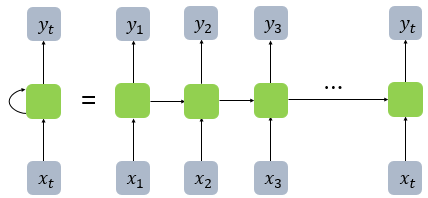
- RNN model
Used for sequential data modeling. (A-B-C-D-?, ? is probably E considered of ahead)
Special types of fully connected neural network.
Connection weights are shared by all layers.


- Encoder
It recieves all the words sequentially, and at the end, it compresses all of these word into A Vector which is called a CONTEXT VECTOR.
- context vector

It recieves all the words and then passed the hidden state at the last point of the Encoder cell to the Decoder, which is called a CONTEXT VECTOR. It is used for the first hidden state of the Decoder cell.
The last point of the Encoder cell meaning it summarizes the information of all the word tokens of input.
There are two main problems.
| - A fixed vector which has compressed all of the information results in information loss. - It has the vanishing gradient. |
- Decoder
When <sos> is input, Decoder predicts the word that is likely to appear next repeatedly until <eos> is predicted by the next word.
It uses the context vector which is the hidden state of the encoder's last RNN cell as the value of the first hidden state.
1. One hidden layer
inputs=(batch_size, len_of_sequence, word_size)
word_size : how many values in the vector after words vectoried
[ [ [ , ] ] ]
(batch_size, len_of_sequence, input_size)
[ [ [ , ] ] ]
(batch_size, len_of_sequence, input_size)
[ [ [ , ] ] ]
(batch_size, len_of_sequence, input_size)
2. Deep Recurrent Neural Network(More than two hidden layers)

nn.RNN(input_size, hidden_size, num_layers, batch_first)
input_size : word_size after vectorized
outputs : first hidden layer status
_status : last hidden layer status
cell=nn.RNN(input_size=5, hidden_size=8, num_layers=2, batch_first=True)
outputs, _status = cell(inputs)
outputs.shape
>>>
torch.Size([1, 10, 8]) #batch_size, len_of_seq, hidden_layer_size_status.shape
>>>
torch.Size([2, 1, 8]) #num_of_layers, batch_size, hidden_layer_size
3. Bidirectional Recurrent Neural Network
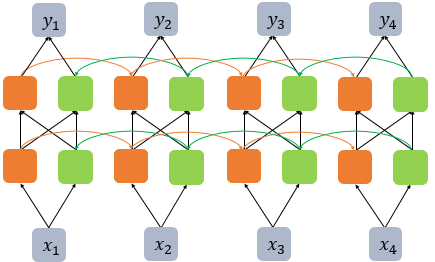
nn.RNN(input_size, hidden_size, num_layers, batch_first, bidirectional)
cell=nn.RNN(input_size=5, hidden_size=8, num_layers=2, batch_first=True, bidirectional=True)
outputs, _status = cell(inputs)
outputs.shape
>>>
torch.Size([1, 10, 16]) #batch_size, len_of_sequence, hidden_layer_size * 2_status.shape
>>>
torch.Size([4, 1, 8]) #num_of_layers * 2, batch_size, hidden_layer_size
-The moment when W becomes smaller than 1, it occurs Vanishing Gradient(exponential decay). -The moment when W becomes bigger than 1, it occurs Gradient Explosion. -It cannot capture long term dependency. |
'Deep Learning > PyTorch' 카테고리의 다른 글
| Pytorch-contiguous (0) | 2022.12.05 |
|---|---|
| PyTorch-permute vs transpose (0) | 2022.12.05 |
| Word2Vec VS Neural networks Emedding (0) | 2022.08.21 |
| PyTorch-randint, scatter_, log_softmax, nll_loss, cross_entropy (0) | 2022.08.10 |
| Linear Regression-requires_grad, zero_grad, backward, step (0) | 2022.08.08 |