Sørensen similarity
- One of Token-based algorithms which is the expected input is a set of tokens, rather than complete strings. The idea is to find the similar tokens in both sets. More the number of common tokens, more is the similarity between the sets. A string can be transformed into sets by splitting using a delimiter. This way, we can transform a sentence into tokens of words or n-grams characters. Note, here tokens of different length have equal importance.
- Falling under set similarity, the logic is to find the common tokens, and divide it by the total number of tokens present by combining both sets.
- Reference : itnext.io/string-similarity-the-basic-know-your-algorithms-guide-3de3d7346227
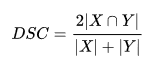
The numerator is twice the intersection of two sets/strings.
The denominator is simple combination of all tokens in both strings.
Note, its quite different from the jaccard’s denominator(2021/03/02 - [Machine Learning] - Jaccard index, Python Jaccard-index), which was union of two strings. As the case with intersection, union too removes duplicates and this is avoided in dice algorithm. Because of this, dice will always overestimate the similarity between two strings.

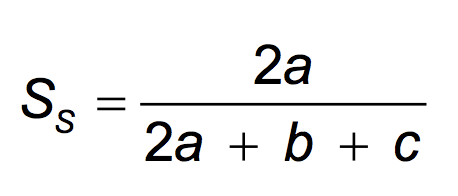
Ss is Sorensen’s similarity coefficient
a,b,c is as defined above in presence-absence matrix
Let’s take this.

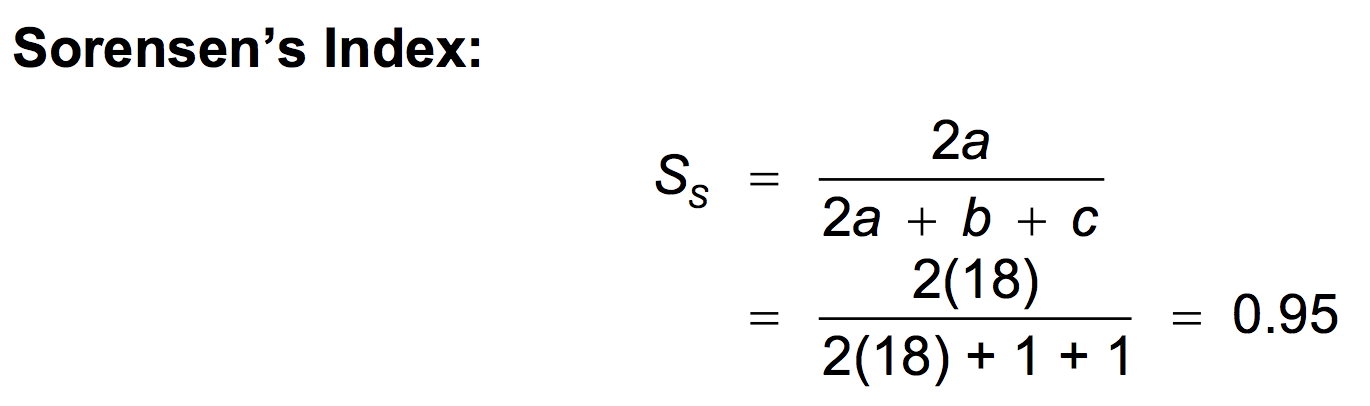
Reference : www.zoology.ubc.ca/~krebs/downloads/krebs_chapter_12_2017.pdf
def compare(first, second):
first=first.replace(' ', '') //remove the white space
second=second.replace(' ', '')
if first==second:
return 1
if len(first)<2 or len(second)<2:
return 0 //if length of first or second is 1 return 0
firstBigrams={} //usind dictionary
for i in range(len(first)-1):
bigram=first[i:i+2] //as first string, i i+1
if bigram in firstBigrams:
firstBigrams[bigram]+=1
else:
firstBigrams[bigram]=1
intersection=0
for i in range(len(second)-1):
bigram=second[i:i+2]
if bigram in firstBigrams and firstBigrams[bigram]>0:
firstBigrams[bigram]-=1
intersection+=1
return (2.0*intersection)/(len(first)+len(second)-2)if __name__=='__main__':
t1="hello new world"
t2="hello world"
print(compare(t1,t2))
>>>0.7619047619047619
- Python Sorensen package
import textdistance
t1="hello world".split()
t2="world hello".split()
textdistance.sorensen(t1,t2)
>>>1.0
t1="hello new world".split()
t2="hello world".split()
textdistance.sorensen(t1,t2)
>>>0.8The result of second case is similar as coding by hand.
'Analyze Data > Measure of similarity' 카테고리의 다른 글
| Vector Similarity-1. cosine similarity (0) | 2021.03.03 |
|---|---|
| Vector Similarity-2. Euclidean distance (0) | 2021.03.03 |
| Vector Similarity-3. Jaccard Similarity (0) | 2021.03.02 |
| Vector Similarity-6. Jaro-Winkler distance (0) | 2021.03.02 |
| Vector Similarity-5. Jaro distance (0) | 2021.02.26 |