- BOW(Bag Of Words)
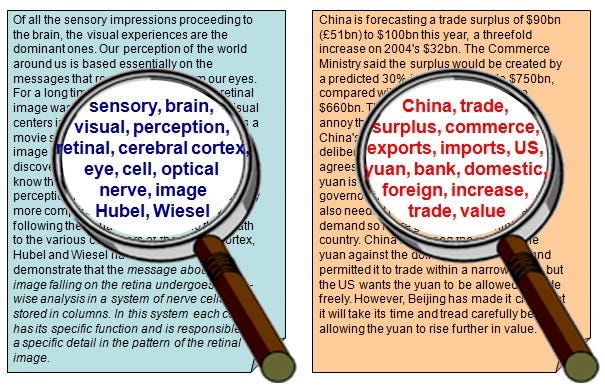
We count the number of each word appears in a document, use the frequency of each word to know the keywords of the document, and make a frequency histogram from it. We treat a document as a bag of words (BOW).
- BOVW(Bag Of Visual Words)

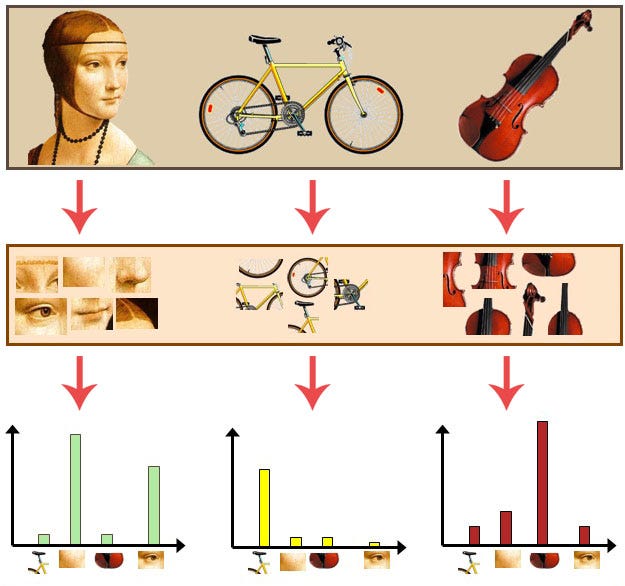
Instead of words, we use image features as the “words”. Image features are unique pattern that we can find in an image.
It is to represent an image as a set of features. Features consists of keypoints and descriptors. We use the keypoints and descriptors to construct vocabularies and represent each image as a frequency histogram of features that are in the image.
- Keypoints
Keypoints are the “stand out” points in an image, so no matter the image is rotated, shrink, or expand, its keypoints will always be the same.
- Descriptor
It is the description of the keypoint.
- Steps to build a bag of visual words (BOVW)
1) Detecting features and extracting descriptors in an image, and build a visual dictionary.

2) Next, we make clusters from the descriptors (we can use K-Means, DBSCAN or another clustering algorithm). The center of each cluster will be used as the visual dictionary’s vocabularies.

3) Finally, for each image, we make frequency histogram from the vocabularies and the frequency of the vocabularies in the image. Those histograms are our bag of visual words (BOVW).

https://towardsdatascience.com/bag-of-visual-words-in-a-nutshell-9ceea97ce0fb
'Deep Learning > Object Detection' 카테고리의 다른 글
| (prerequisite-Fast R-CNN) Truncated SVD (0) | 2024.01.26 |
|---|---|
| SPPNet (0) | 2024.01.24 |
| R-CNN (0) | 2024.01.23 |
| (prerequisite-R-CNN) Non-maximum Suppression(NMS) (0) | 2024.01.23 |
| (prerequisite-R-CNN) Bounding Box Regression (0) | 2024.01.23 |