- SPPNet(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
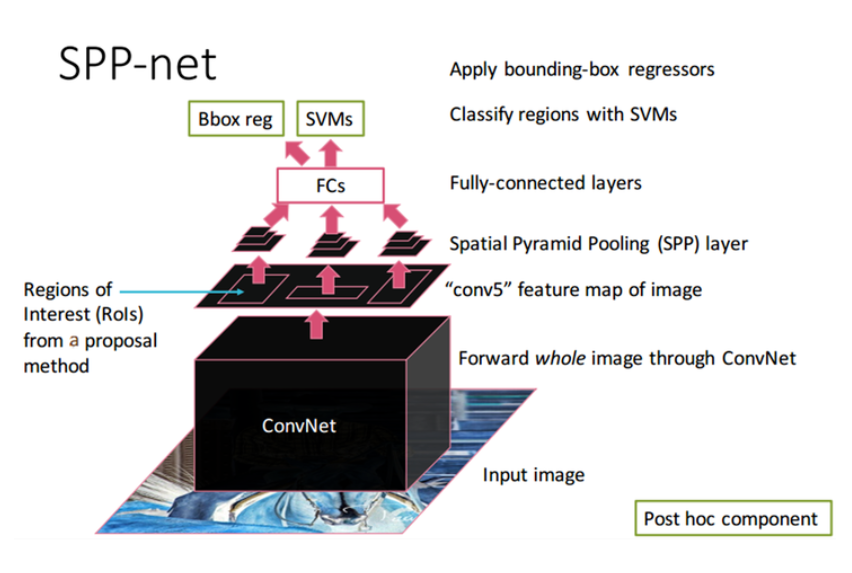
1. Region proposals : Extract RoI(2,000) apply with Selective Search to the image
2. CNN : Input the image to ConvNet without crop & warp, get the Feature map(256).
3. Scale-down all the RoI(2,000) and map on the Feature map.
4. RoI Feature : Extract the RoI from the Feature map.
5. SPP : Apply the RoI Feature to the SPP.
6. SVM : Classify the vectors with SVM.
7. Bounding Box Regression : Resize the bounding box with Bounding Box Regression
8. Non-maximum suppression : Select the final bounding box.
- SPPnet appearance background

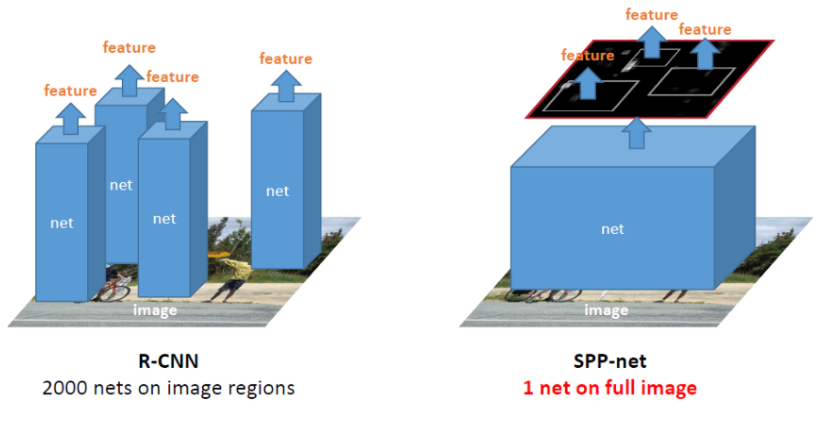
To overcome this issue-the fixed size constraint of a CNN network, it replaced the last pooling layer (the one just before the FC layer) with a Spatial Pyramid Pooling(SPP) layer. The SPP approach is inspired by the Bag of Words approach.
- RoI is mapped to the feature map
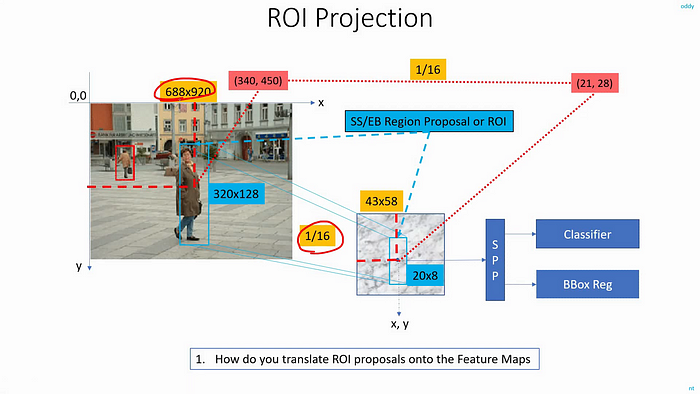
In this way, we can map any object from the input image to the output feature map. The object’s coordinates are also projected to the feature map, and only that region are then sent to the SPP layer for feature extraction and then to the FC layer.
- Let the image size be [img_height, img_width] ↔ [688 x 920]
- Let an object present in the image have the center at [x, y]↔[340, 450]
- The height and width of the above object is [obj_height, obj_width]↔[320, 128]
- Now to map them to the corresponding spatial location on the feature map, we simply multiply them with the sub-sampling ratio (S)↔16.
- The feature map will be of size [img_height * S, img_width * S]↔[43 x 58]
- The object center on the feature map will be in the spatial location of [x * S, y * S]↔[21, 28]
- The height and width of the object on the feature map will have a height and width of [obj_height * S, obj_width * S] ↔[20 x 8]
- Spatial Pyramid Pooling(SPP)

If you make the pooling window and stride proportional to the input image, you can always get a fixed-sized output. Moreover, the SPP layers do not just apply one pooling operation, it applies a couple of different output sized pooling operations (that’s where then same comes from — Spatial Pyramid Pooling) and combines the results before sending them to the next layer.

It has used three pooling operations, where one of them outputs only a single number for each map. This operation is applied to each feature map (256 maps in the above case) given out by the previous convolution operation. The SPP layer output is flattened and send to the FC layer.
'Deep Learning > Object Detection' 카테고리의 다른 글
| Fast RCNN (0) | 2024.01.29 |
|---|---|
| (prerequisite-Fast R-CNN) Truncated SVD (0) | 2024.01.26 |
| (prerequisite-SPPNet) BOVW(Bag Of Visual Words) (0) | 2024.01.24 |
| R-CNN (0) | 2024.01.23 |
| (prerequisite-R-CNN) Non-maximum Suppression(NMS) (0) | 2024.01.23 |