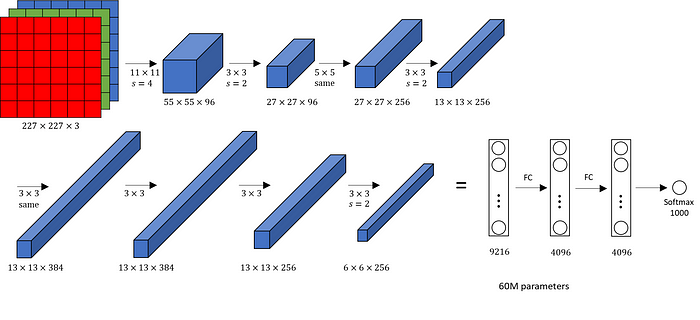
- AlexNet
- It consists of 5 convolution layers, 3 max-pooling layers, 2 Normalized layers, 2 fully connected layers and 1 SoftMax layer.
- Each convolution layer consists of a convolution filter and a non-linear activation function called “ReLU”.
- The pooling layers are used to perform the max-pooling function
- and the input size is fixed due to the presence of fully connected layers. The input size is mentioned at most of the places as 227x227x3.

- Key features
- ‘ReLU’ is used as an activation function rather than ‘tanh’
- Batch size of 128
- SGD Momentum is used as a learning algorithm
- Data Augmentation is been carried out like flipping, jittering, cropping, colour normalization, etc.
https://medium.com/@siddheshb008/alexnet-architecture-explained-b6240c528bd5
https://velog.io/@lighthouse97/AlexNet%EC%9D%98-%EC%9D%B4%ED%95%B4
'Deep Learning > CNN' 카테고리의 다른 글
| LeNet-5 (0) | 2024.01.04 |
|---|---|
| ResNet (0) | 2024.01.03 |
| VGG16 (0) | 2023.12.14 |
| (prerequisite-RoIs) Interpolation, Linear Interpolation, Bilinear Interpolation, ZOH(Zero-order Hold Interpolation) (0) | 2023.07.04 |
| CNN (0) | 2023.01.20 |