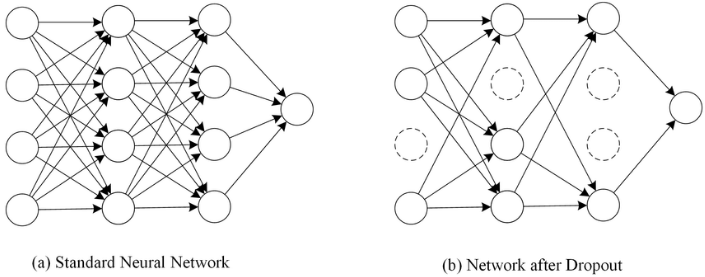
- Dropout
- One way to avoid overfitting, using several neurons only rather than whole neurons when machine training.
- It does not have any learnable parameters and has only one hyperparameter.
- It does not behave similarly during training and testing. To be understand this, let us consider a simple fully connected layer containing 10 neurons. We are using a dropout probability of 0.5. Well during training, a neuron in the next fully connected layer will on average receive an input from 5 neurons. However, during testing, the same neurons will receive an input from 10 neurons. To get a similar behavior during training and testing, we need to scale the neuron's output by 0.5 during testing time.
model = Sequential()
model.add(Dense(256, input_shape=(max_words,), activation='relu'))
model.add(Dropout(0.5)) # add dropout, 50%
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5)) # add dropout, 50%
model.add(Dense(num_classes, activation='softmax'))
- Gradient Clipping
It is a technique to prevent exploding gradients in very deep networks, usually in recurrent neural networks. It prevents any gradient to have norm greater than the threshold and thus the gradients are clipped.
from tensorflow.keras import optimizers
Adam = optimizers.Adam(lr=0.0001, clipnorm=1.)
- Weight Initialization
The aim of weight initialization is to prevent layer action outputs from exploding or vanishing during the course of a forward pass through a deep neural network. If either occurs, loss gradients will either be too large or too small to flow backwards beneficially, and the network will take longer to converge.
1. Xavier
It initializes the weights in your network by drawing them from a distribution with zero mean and a specific variance.
Between incoming layer(nin) and outgoing layer(nout). It would maintain the variance of activation and back-propagated gradients all the way up or down the layers.
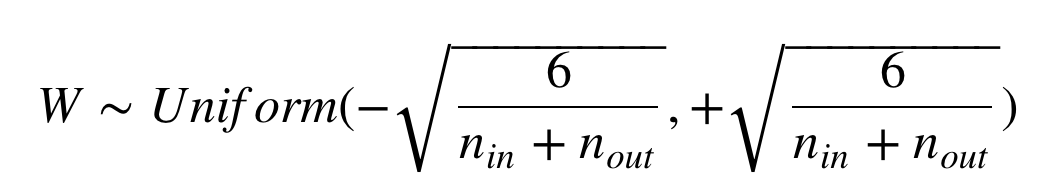
When initialize to normal distribution, standard deviation(σ) should be this.
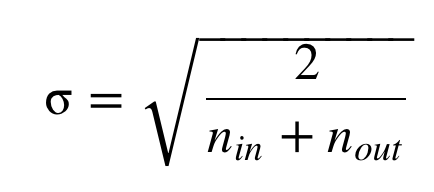
2. He
It is initialized the previous layer which helps in attaining a global minimum of the cost function faster.The weights are still random but differ in range depending on the size of the previous layer of neurons.
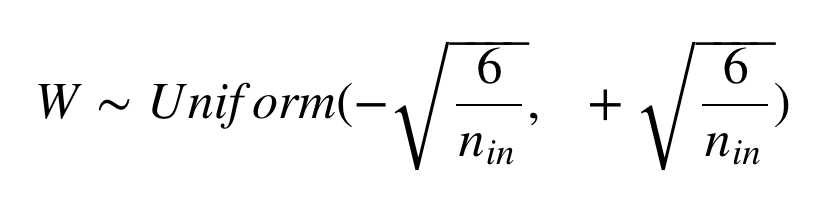
When initialize to normal distribution, standard deviation(σ) should be this.
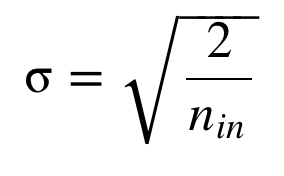
- Batch Normalization
An algorithmic method which makes the training of Deep Neural Networks (DNN) faster and more stable.
It consists of normalizing activation vectors from hidden layers using the first and the second statistical moments (mean and variance) of the current batch. This normalization step is applied right before (or right after) the nonlinear function.
1. Internal Covariate Shift
The change in the distribution between training and testing set.
Assuming we only have “common” cars for training. How would the model react if we ask it to classify a formula 1 car? In this example, there is a shift between the training and testing distribution.
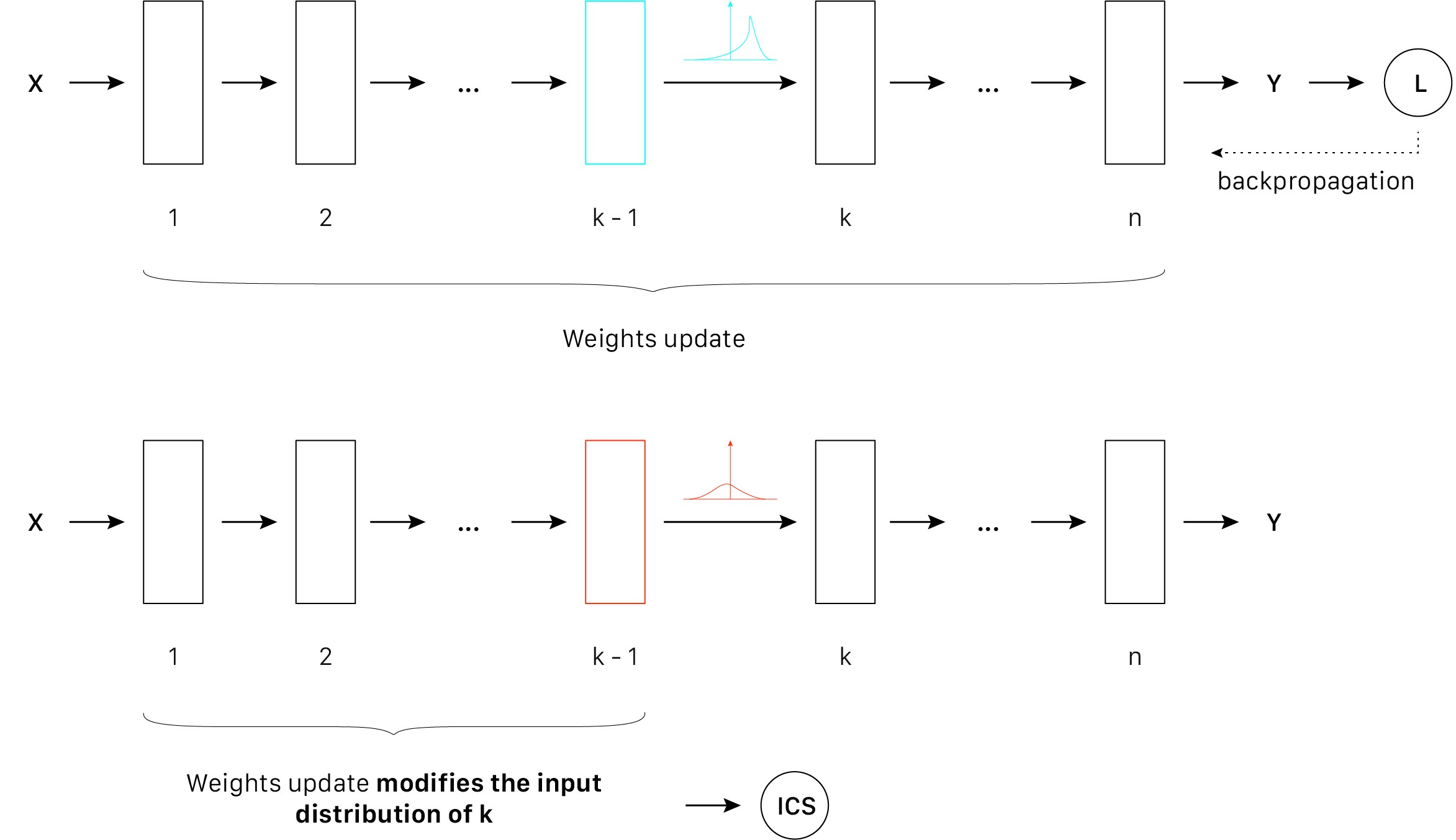
If there is a huge covariate shift in the input signal, the optimizer will have trouble generalizing well. On the contrary, if the input signal always follows a standard normal distribution, the optimizer will more easily generalize.
reference : towardsdatascience.com/batch-normalization-in-3-levels-of-understanding-14c2da90a338
2. Batch Normalization
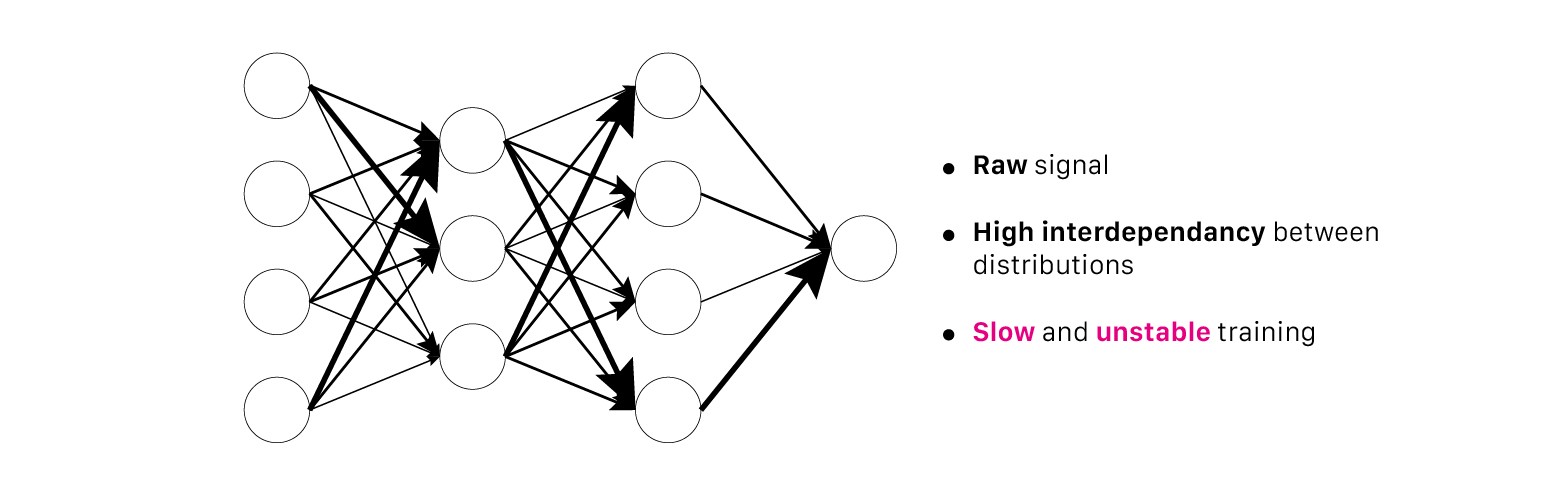
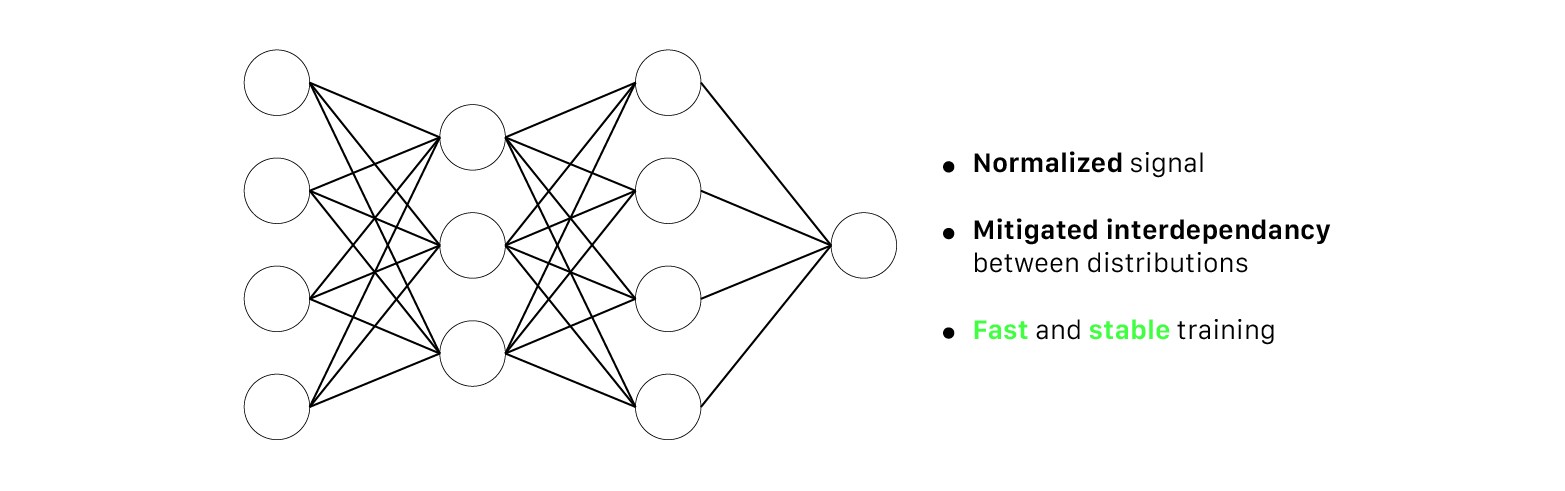
It focuses on standarizing the inputs to any particular layer(i.e. activations from previous layers). Standardizing the inputs mean that inputs to any layer in the network should have approximately zero mean. Mathematically, BN layer transforms each input in the current mini-batch by subtracting the input mean in the current mini-batch and dividing it by the standard deviation.
It normalize layers per batch size. It implements before layer through the acrivation function. It makes input mean as 0, and then implements scale(γ) and shift(β).

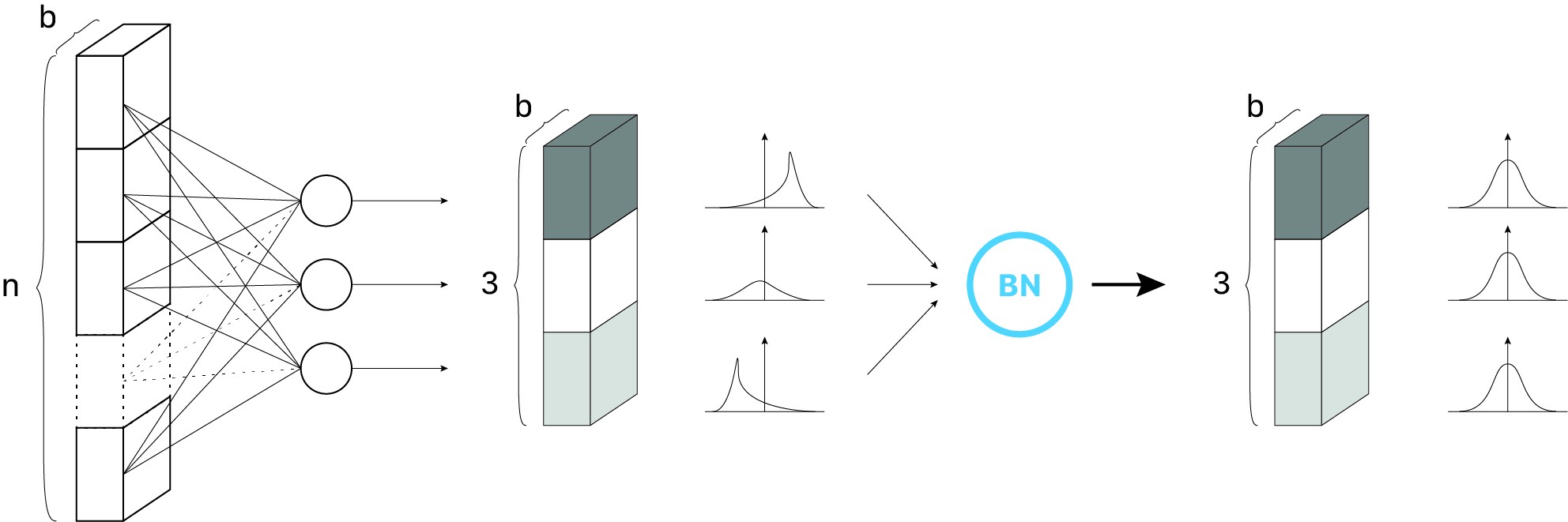
towardsdatascience.com/batch-normalization-in-3-levels-of-understanding-14c2da90a338#e5ba
- Layer Normalization
It normalizes the activations along the feature direction instead of mini-batch direction. This overcomes the cons of BN by removing the dependency on batches. In essence, LN normalizes each feature of the activations to zero mean and unit variance.
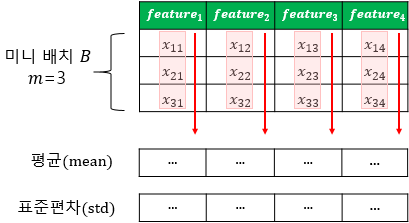
- mini-batch
Numbers of samples with the same number of features.
- Layer Normalization

reference : towardsdatascience.com/different-normalization-layers-in-deep-learning-1a7214ff71d6
'Deep Learning' 카테고리의 다른 글
| Activation function (0) | 2022.03.17 |
|---|---|
| sklearn (0) | 2022.03.08 |
| Forward Propagation, Forward Propagation Computation (0) | 2021.04.07 |
| Forward Propagation, Batch Gradient, Stochastic Gradient Descent, SGD, Mini Batch Gradient Descent, Momentum, Adagrad, Rprop, RMSprop, Adam, Epoch, Batch size, Iteration (0) | 2021.04.06 |
| FFNN, RNN, FCNNs (0) | 2021.04.05 |