- Jaro distance
- One of edit distance based algorithms which is falling under this category try to compute the number of operations needed to transforms one string to another. More the number of operations, less is the similarity between the two strings. One point to note, in this case, every index character of the string is given equal importance.
- A string metric for measuring the edit distance between two sequences.
- The distance between two words is the minimum number of single-character transpositions required to change one word into the other.
Reference : medium.com/@appaloosastore/string-similarity-algorithms-compared-3f7b4d12f0ff
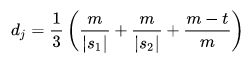
dj is the Jaro distance
m is the number of matching characters (characters that appear in s1 and in s2)
t is half the number of transpositions (compare the i-th character of s1 and the i-th character of s2 divided by 2)
|s1| is the length of the first string
|s2| is the length of the second string
Let’s take “martha” and “marhta”.
m = 6
t = 2/2 =1 (2 couples of non matching characters,in otder words, the number of transposition, the 4-th and 5-th) { t/h ; h/t }
|s1| = 6
|s2| = 6Just by replacing numbers is the formula, we get :
dj = (⅓) ( 6/6 + 6/6 + (6–1)/6) = ⅓ 17/6 = 0,944
Jaro distance = 94,4%from __future__ import division
def jaro(s,t):
s_len=len(s)
t_len=len(t)
if s_len==0 and t_len==0:
return 1
match_distance=(max(s_len, t_len)//2)-1
s_matches=[False]*s_len
t_matches=[False]*t_len
matches=0
transpositions=0
for i in range(s_len):
start=max(0,i-match_distance)
end=min(i+match_distance+1, t_len)
for j in range(start, end):
if t_matches[j]:
continue
if s[i]!=t[j]:
continue
s_matches[i]=True
t_matches[j]=True
matches+=1
break
if matches==0:
return 0
k=0
for i in range(s_len):
if not s_matches[i]:
continue
while not t_matches[k]:
k+=1
if s[i]!=t[k]:
transpositions+=1
k+=1
return ((matches/s_len)+(matches/t_len)+((matches-transpositions/2)/matches))/3
def main():
for s,t in [('MARTHA', 'MARHTA'),
('DIXON', 'DICKSONX'),
('JELLYFISH', 'SMELLYFISH')]:
print('jaro distance(%r, %r)=%.10f'%(s,t,jaro(s,t)))
if __name__=='__main__':
main()
>>>jaro distance('MARTHA', 'MARHTA')=0.9444444444
>>>jaro distance('DIXON', 'DICKSONX')=0.7666666667
>>>jaro distance('JELLYFISH', 'SMELLYFISH')=0.8962962963Reference : rosettacode.org/wiki/Jaro_distance#Python
from __future__ : The aim of improving the language over the long term, the futurue statement is intended to ease migration to future versions of Python that introduce incompatible changes to the language. It allows use of the new features on a per-module basis before the release in which the feature becomes standard.
__name__ : __name__ variable will be set as __main__ if the module that is being run is the main program. But if the code is importing the module from another module, then the __name__ variable will be set to that module's name.
Reference : www.freecodecamp.org/news/if-name-main-python-example/
def jaro_distance(s1,s2):
if (s1==s2):
return 1.0
len1=len(s1)
len2=len(s2)
max_dist=floor(max(len1, len2)/2)-1
match=0
hash_s1=[0]*len(s1)
hash_s2=[0]*len(s2)
for i in range(len1):
for j in range(max(0,i-max_dist),min(len2, i+max_dist+1)):
if (s1[i]==s2[j] and hash_s2[j]==0):
hash_s1[i]=1
hash_s2[j]=1
match+=1
break
if (match==0):
return 0.0
t=0
point=0
for i in range(len1):
if (hash_s1[i]):
while (hash_s2[point]==0):
point+=1
if (s1[i]!=s2[point]):
point+=1
t+=1
t//2
return (match/len1+match/len2+(match-t+1)/match)/3.0
s1='CRATE'
s2='TRACE'
print(round(jaro_distance(s1,s2),6))
>>>0.511111Reference : www.geeksforgeeks.org/jaro-and-jaro-winkler-similarity/
'Analyze Data > Measure of similarity' 카테고리의 다른 글
| Vector Similarity-2. Euclidean distance (0) | 2021.03.03 |
|---|---|
| Vector Similarity-7. Sørensen similarity (0) | 2021.03.02 |
| Vector Similarity-3. Jaccard Similarity (0) | 2021.03.02 |
| Vector Similarity-6. Jaro-Winkler distance (0) | 2021.03.02 |
| Vector Similarity-4. Levenshtein distance (0) | 2021.02.25 |