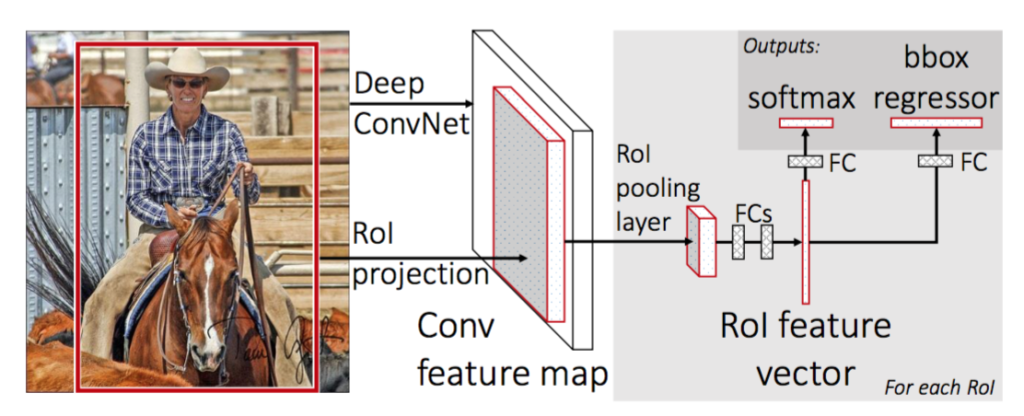
- Fast RCNN
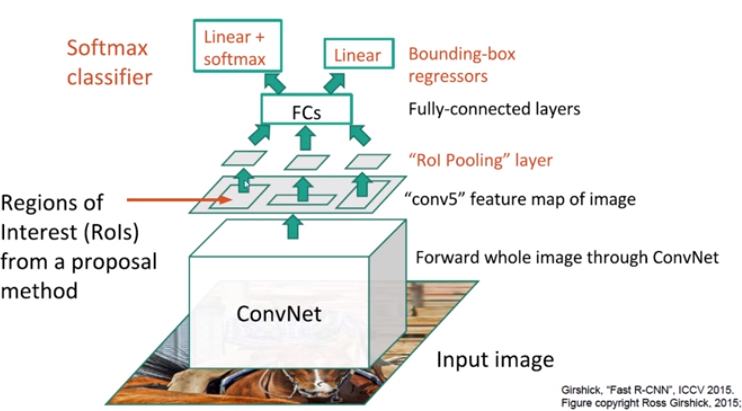
1. Region proposals : Extract RoI(2,000, 500 x 700) apply with Selective Search to the image
2. CNN(VGG16) : Input the image(224x224x3) to ConvNet without crop & warp, get the Feature map(14x14x512).
3. Scale-down all the RoI(2,000) to 1/100(Sub-Sampling Ratio).
4. RoI Projection : While Region proposals have not gone throuth the Sub-Sampling process, Feature map went through the Sub-Sampling process several times and became smaller in size.
5. RoI Feature Map
6. Divide the RoI Feature Map by grid
7. Get the Feature Map(7x7x512) from the each cells.
8. Fletten the Feature Map(7 x 7 x 512 = 25088)
9. FC Layer : Get the Feature Vector(4096)
10.Final FC layer is replaced by two branches
- a (K + 1) category Softmax layer branch
- a category specific Bounding Box Regression branch.
11. Multi-task loss
- VGG backbone
- Structure of VGG16

- Finetuned Structure of VGG16 for Fast RCNN

- Input : 224x224x3 sized image
- Process : feature extraction by VGG16
- Output : 14x14x512 feature maps
- RoI(Region of Interest) Pooling
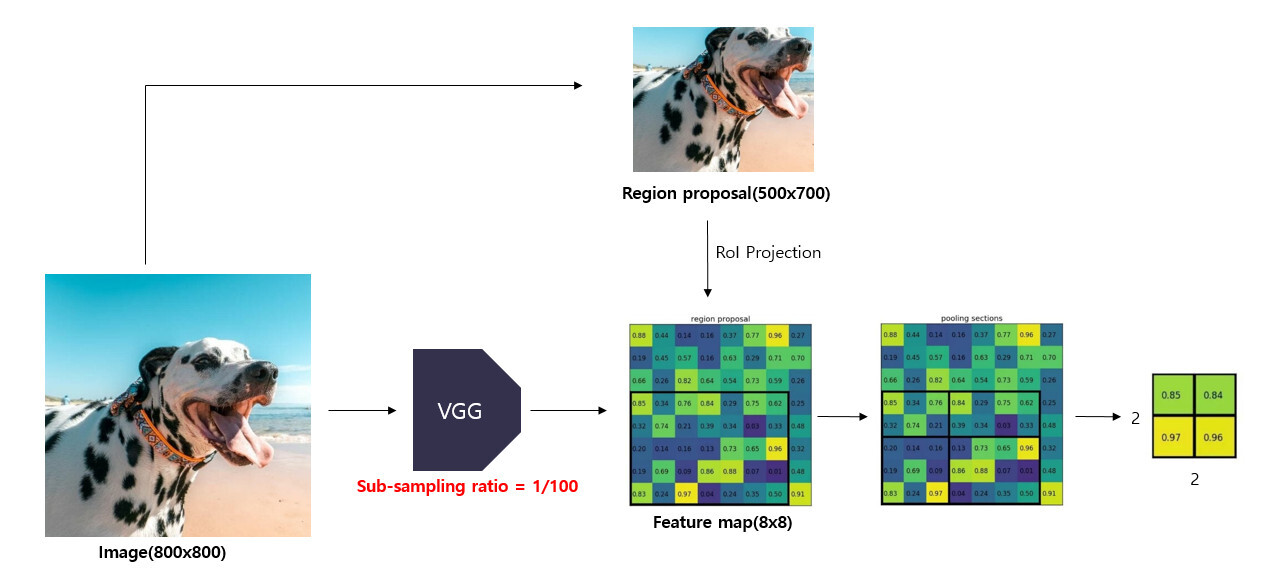
Example of the image above.
1) VGG16 : Get the Feature Map(8 x 8)
2) Apply Sub-Sampling Ratio(1/100) to the Feature Map
3) Region Proposals : With the Selective search(500x700)
4) RoI Projection
Step 1) In order to find the Region Proposal area in the smaller feature map, it is necessary to change the size and center coordinates, width, height of the Region Proposal to match with the Sub-Sampling Ratio.
Step 2) Then project it on the Fearue Map.
Step 3) RoI Feature Map : Match the resized Region Proposal with the Feature Map and extract it(5 x 7).
Step 4) Divide the RoI Feature Map by Grid to match the size of the specified Sub-Window(2x2).
Step 5) Get the Feature Map from each Grid cells by Max Pooling.

- Input : 14x14 sized 512 feature maps, 2000 region proposals
- Process : RoI pooling
- Output : 7x7x512 feature maps
- Hierarchical Sampling
- N : Sampling Images, 2
- R : Region Proposal from N, 128
- Sampling : R/N, 128/2=64
- 25% of the ROIs are object proposals that have at least 0.5 IoU with a ground-truth bounding box of a foreground class. These would be positive for that particular class and would be labelled with the appropriate u=1…K.
- The remaining ROIs are sampled from proposals that have an IoU with groundtruth bounding boxes between [0.1, 0.5). These ROIs are labelled as belonging to the class u = 0 (background class).
- Feature vector extraction by Fc layers
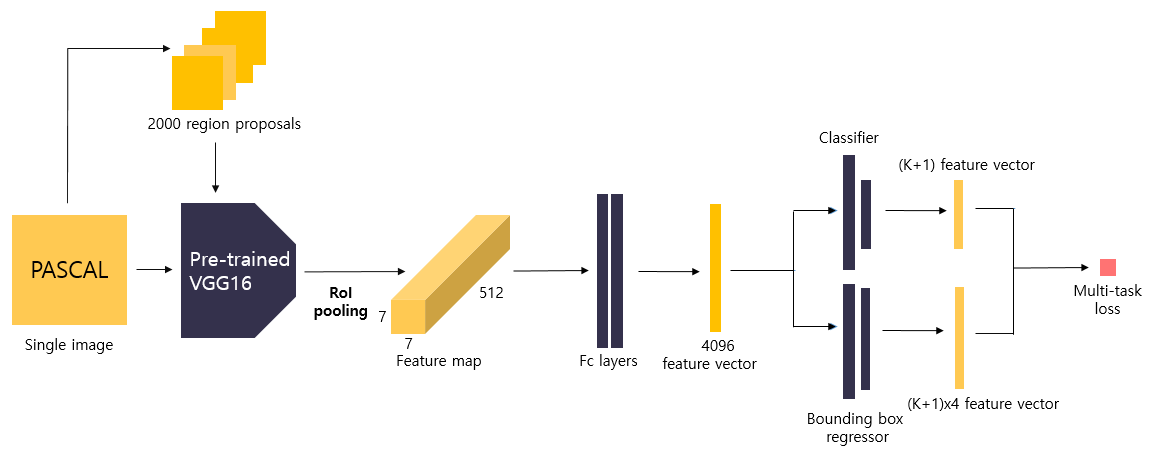
- Input : 7x7x512 sized feature map
- Process : feature extraction by fc layers
- Output : 4096 sized feature vector
- Class prediction
- Input : 4096 sized feature vector
- Process : class prediction by Classifier
- Output : (K+1) sized vector(class score)
- Detailed localization by Bounding box regressor
- Input : 4096 sized feature vector
- Process : Detailed localization by Bounding box regressor
- Output : (K+1) x 4 sized vector
- Truncated SVD

The large fully connected layers can be compressed with truncated SVD to make the network more efficient.
If the weight matrix of FC layer is , it can be approximated through Truncated SVD. This makes it possible to reduce the number of parameters from to . When truncated SVD is applied to the weight matrix , the FC layer is divided into two FC layers. The first fc layer is , and the second fc layer is .- Multi-task loss
- Input : (K+1) sized vector(class score), (K+1) x 4 sized vector
- Process : calculate loss by Multi-task loss function
- Output : loss(Log loss + Smooth L1 loss)
The joint multi-task loss for each ROI is given by the combination of the two losses-Soft Max and Bounding Box Regression.
The regression branch produces 4 bounding box regression offsets tᵏᵢ where i = x, y, w, and h. (x, y) stands for the top-left corner and w and h denote the height and width of the bounding box.
The true bounding box regression targets for a class u are indicated by vᵢ where i = x, y, w, and h when u≥1. The case where u=0 is ignored because the background classes have no groundtruth boxes.
https://herbwood.tistory.com/8
https://ganghee-lee.tistory.com/36
https://towardsdatascience.com/fast-r-cnn-for-object-detection-a-technical-summary-a0ff94faa022
'Deep Learning > Object Detection' 카테고리의 다른 글
| (prerequisite-YOLO) DarkNet (0) | 2024.02.11 |
|---|---|
| Faster RCNN (0) | 2024.01.30 |
| (prerequisite-Fast R-CNN) Truncated SVD (0) | 2024.01.26 |
| SPPNet (0) | 2024.01.24 |
| (prerequisite-SPPNet) BOVW(Bag Of Visual Words) (0) | 2024.01.24 |