- YOLO(You Only Look Once)

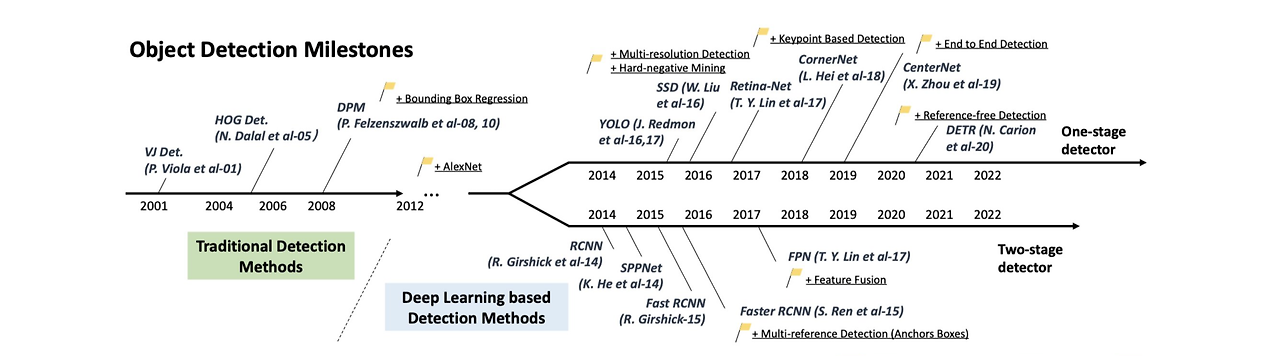
1. Devide the cell to the grid evenly
2. The grid cell which has the center of the object is assigned to detect that object(two red dots on the rightmost pic).
3. Each grid cell predict the bounding box and confidence score of bounding box. (Higher confidence score, thicker bounding box (The picture above (4)) ).
4. At the same time, classification is carried out simultaneously.
5. Leaves thick boxes only and erases thin boxes, which are less likely to have objects.
6. NMS(Non-Maximum Suppression)
- Confidence Score
The number that whether the bounding box contains objects or not, and how accurately the box predicts the ground truth box.
If there is an object in the grid cell, the confidence score is equal to the IoU value.
Conversely, if there is no object in the grid cell, the confidence score will be zero.
- Predictions on a grid
Bounding boxes are similar to anchor boxes in Faster RCNN.
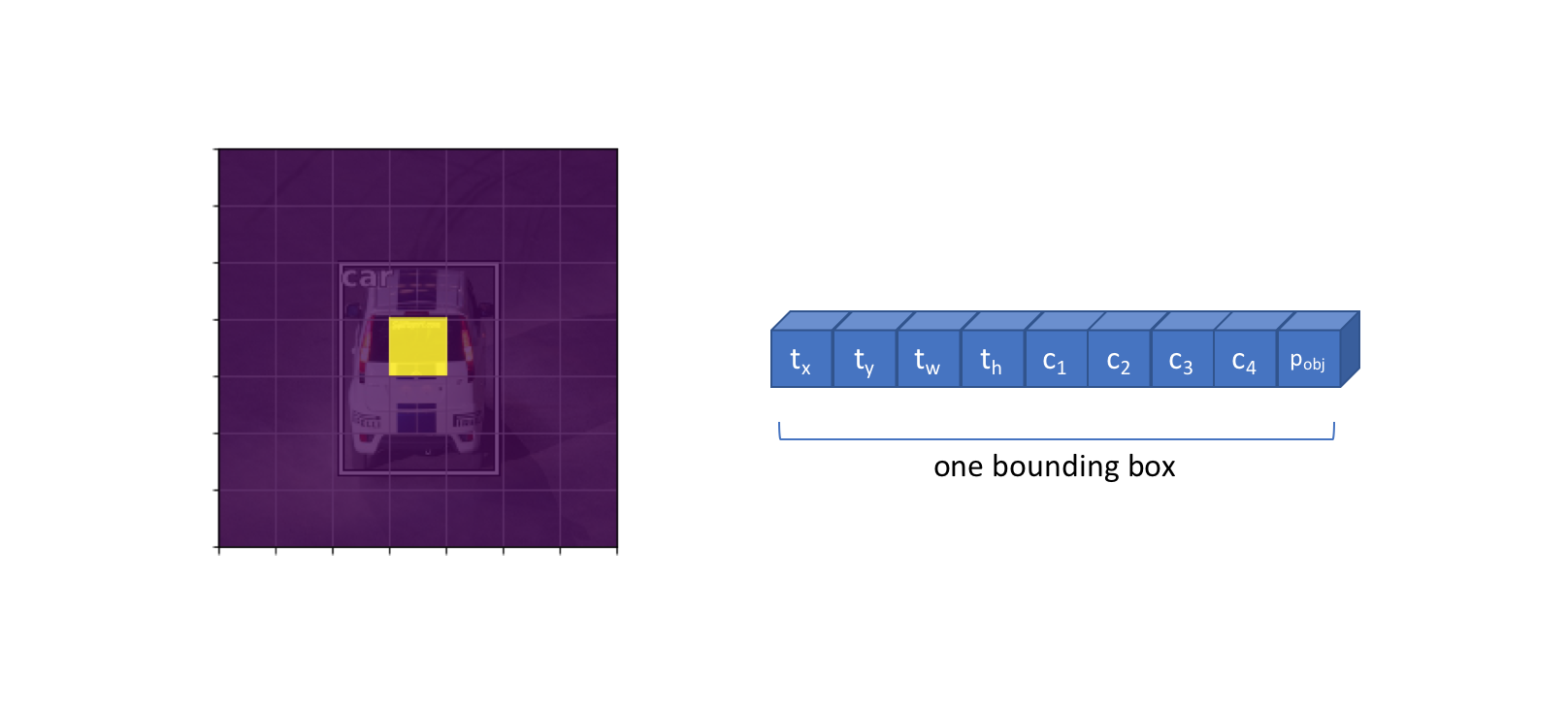
They consists in five prediction-4 spatial coordinates, one objectness score.
A single cell contain only one object.
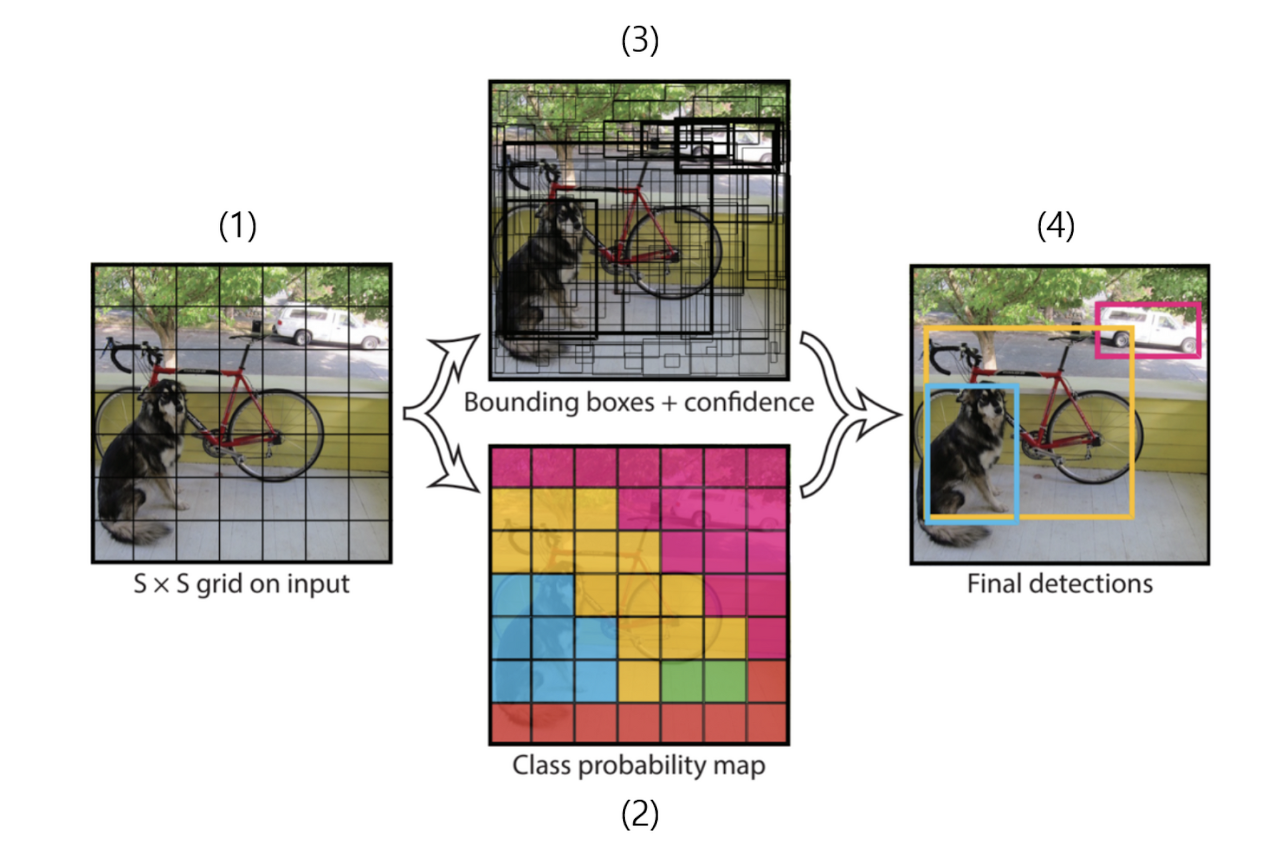
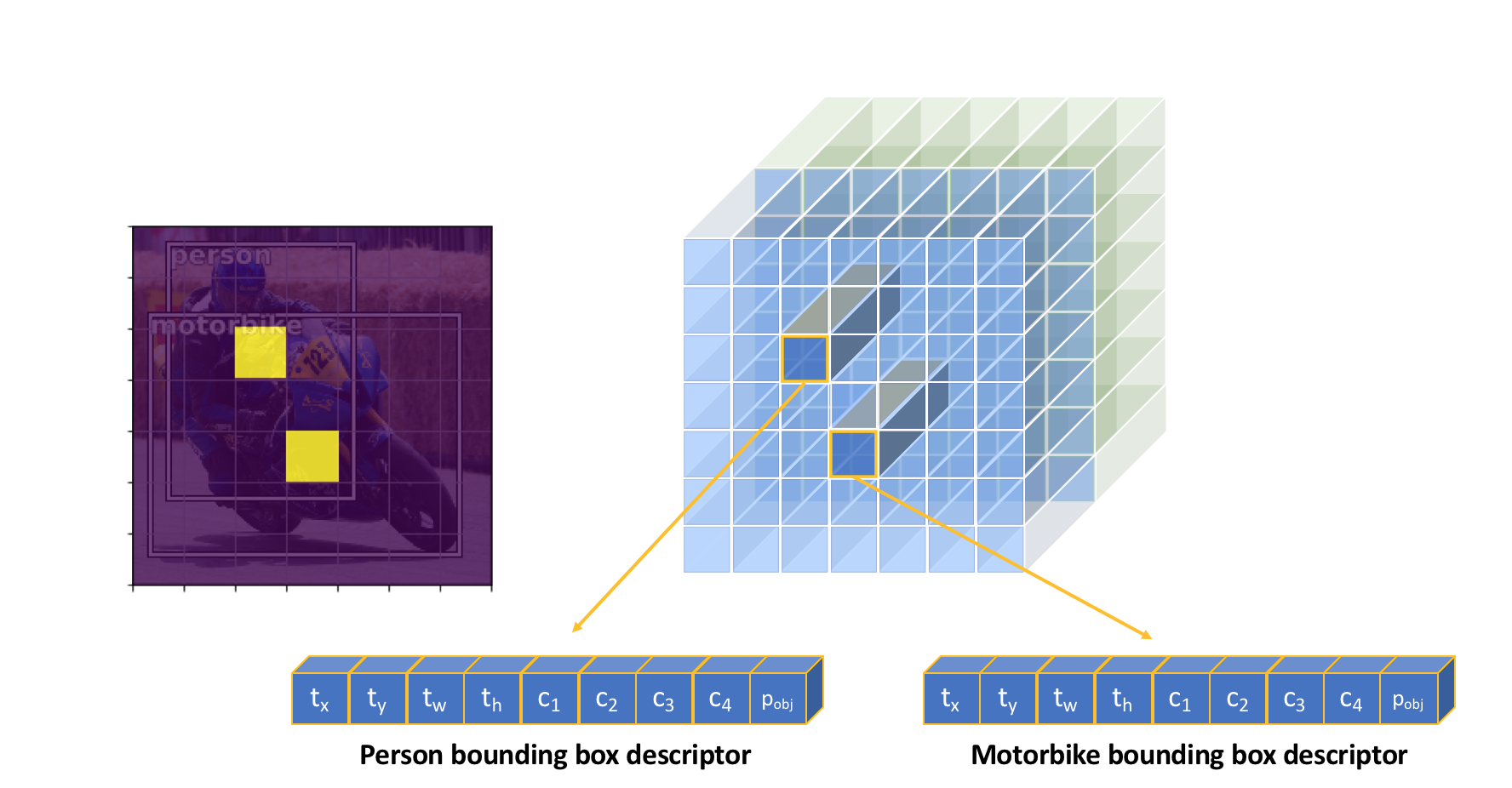
- Which class the object belongs to , , ... , - The likelihood that a grid cell contains an object - Four bounding box descriptors to describe the coordinate, coordinate, width, and height of a labeled box , , ,
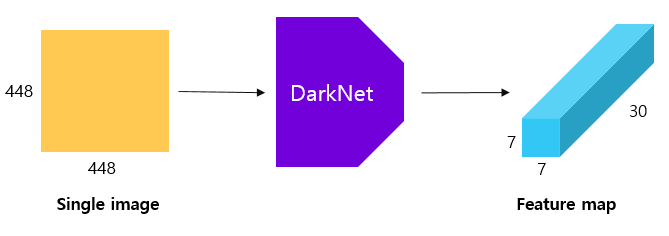
Example
- First bounding box
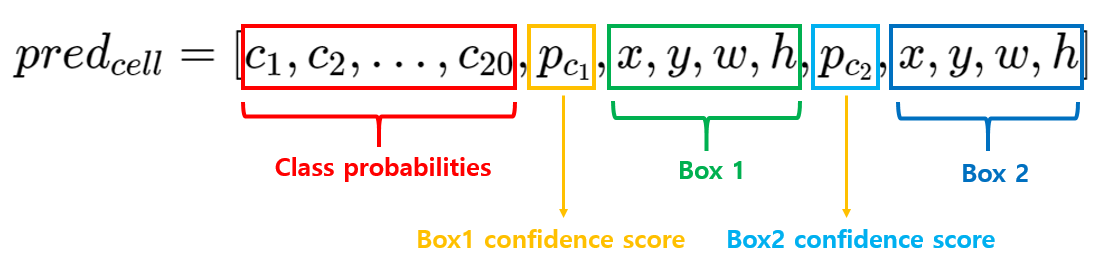
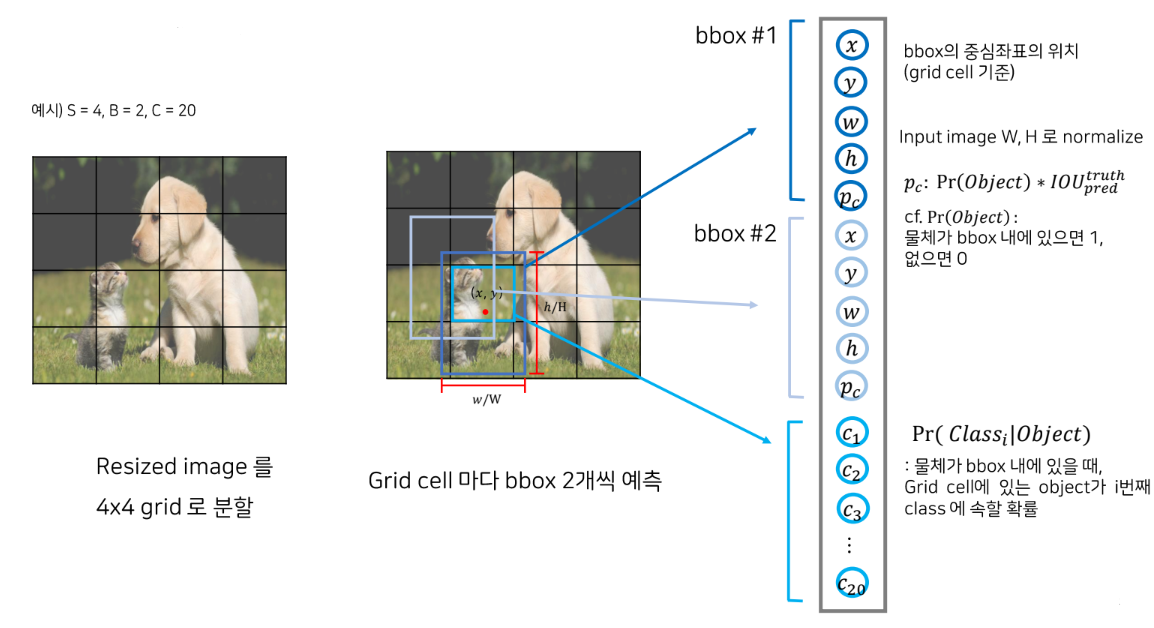
1. Devide the cell to 4*4 grid evenly
2. Each cell has 2 bounding boxes
3. Assume that there are 20 classes
4. Output(5 values)
- x, y : Center coordinate of predicted bounding box
- w, h : Normarlized width, height
- Pc : Confidence score
- Second bounding box.
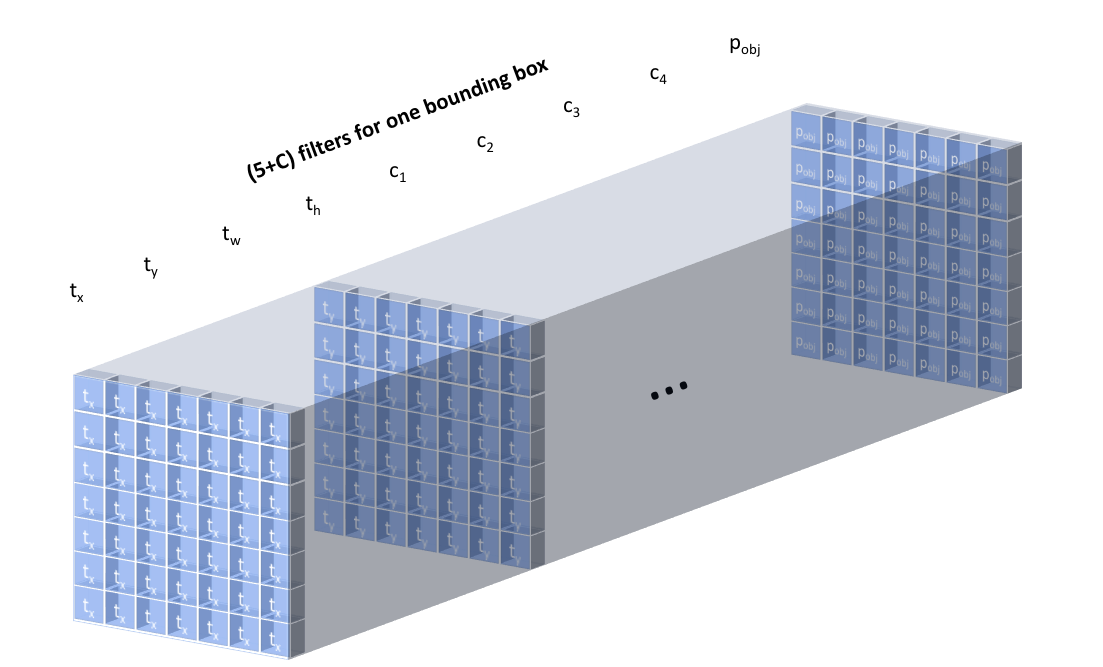
Put the 5 values into an one-dimensional tensor.

The full output of applying convolutional filters is shown below for clarity, producing one bounding box descriptor for each grid cell.
- Output tensor of 2 bounding boxes
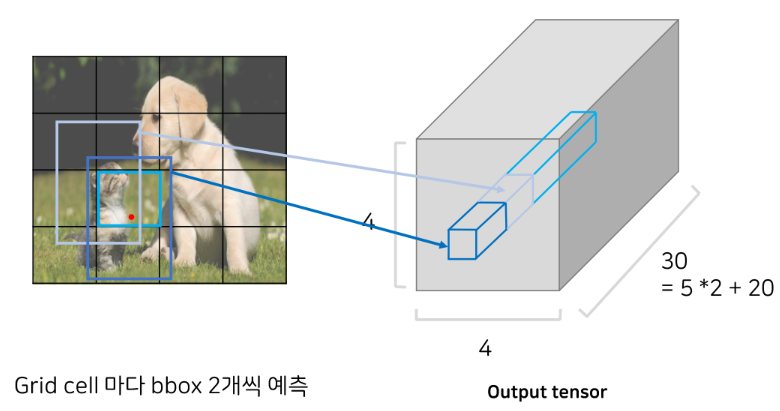
- Output tensor of multiple bounding boxes
- Training Stage

1) Responsible cell(sky blue cell) for a specific object is assigned to the cell where the center coordinates of the ground truth box are located.
2) In the sky blue cell, select one bounding box based on the IOU value.
3) Calculate loss function between selected box(from 2)) and ground truth box.
- SSE(Sum of Squared Error)
Loss function for YOLO v1, sum of Localization loss, Confidence loss, Classification loss.
- Localization loss

- : 많은 grid cell은 객체를 포함하지 않아 confidence score가 0이 되어 객체를 포함하는 grid cell의 gradient를 압도하여, 모델이 불안정해질 수 있습니다. 는 이러한 문제를 해결하기 위해 객체를 포함하는 cell에 가중치를 두는 파라미터입니다. 논문에서는 5로 설정 - : grid cell의 수(=7x7=49) - : grid cell별 bounding box의 수(=2) - : 번째 grid cell의 번째 bounding box가 객체를 예측하도록 할당(responsible for)받았을 때 1, 그렇지 않을 경우 0인 index parameter입니다. 앞서 설명했듯이 grid cell에서는 B개의 bounding box를 예측하지만 그 중 confidence score가 높은 오직 1개의 bounding box만을 학습에 사용합니다. - : ground truth box의 x, y 좌표와 width, height. 여기서 크기가 큰 bounding box의 작은 오류가 크기가 작은 bounding box의 오류보다 덜 중요하다는 것을 반영하기 위해 값에 루트를 씌어주게 됩니다. - : 예측 bounding box의 x, y 좌표, width, height
- Confidence loss
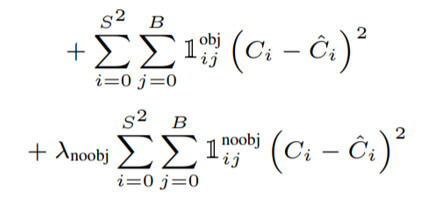
- : 앞서 언급한 객체를 포함하지 않는 grid cell에 곱해주는 가중치 파라미터입니다. 논문에서는 =0.5로 설정 로 설정한 것에 비해 상당히 작게 설정하여 객체를 포함하지 않은 grid cell의 영향력을 줄였습니다. - : 번째 grid cell의 번째 bounding box가 객체를 예측하도록 할당(responsible)받지 않았을 때 1, 그렇지 않을 경우 0인 index parameter입니다. - : 객체가 포함되어 있을 경우 1, 그렇지 않을 경우 0 - : 예측한 bounding box의 confidence score
- Classification loss

- : 실제 class probabilities - : 예측한 class probabilities
https://dotiromoook.tistory.com/24
'Deep Learning > Object Detection' 카테고리의 다른 글
| Image Intensity, Canny (0) | 2024.05.28 |
|---|---|
| Object Detection, mAP(The Mean Average Precision) (0) | 2024.02.16 |
| (prerequisite-YOLO) One Stage Object Detection (0) | 2024.02.11 |
| (prerequisite-YOLO) DarkNet (0) | 2024.02.11 |
| Faster RCNN (0) | 2024.01.30 |