- DarkNet
It inspired by the structure of GoogleNet.
It has been designed for generating a final feature map that fits the size of the prediction, 7x7x30 for YOLO v1.
It consists of a total of 24 conv layers and 2 fc layers.
DarkNet trained by ImageNet dataset.
- Image size
- 224x224 : When it trains for classification task.
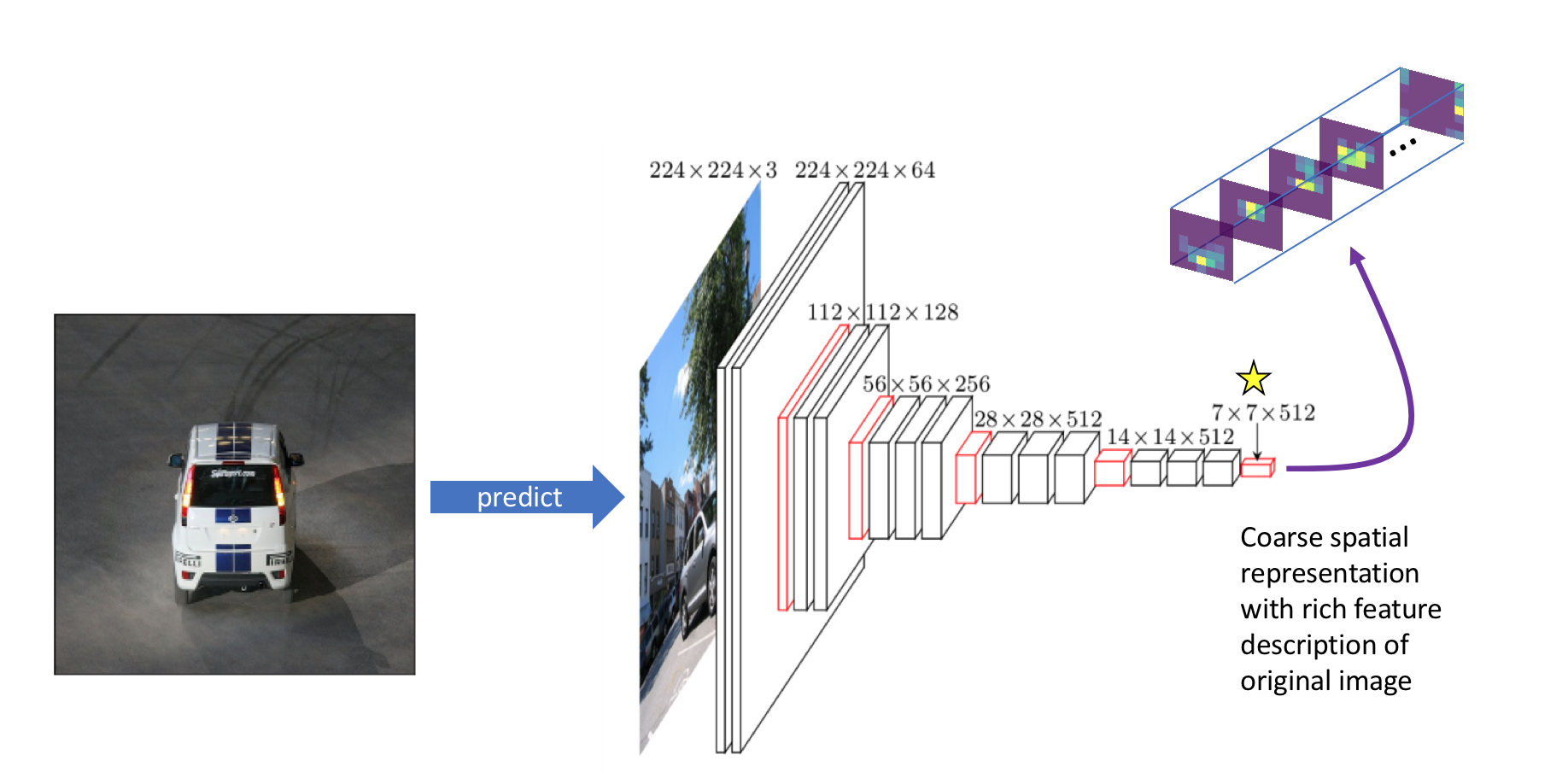
https://www.jeremyjordan.me/object-detection-one-stage/
- 448x448 : When it trains for detection task, increase the size of the image for refinement to improve performance.
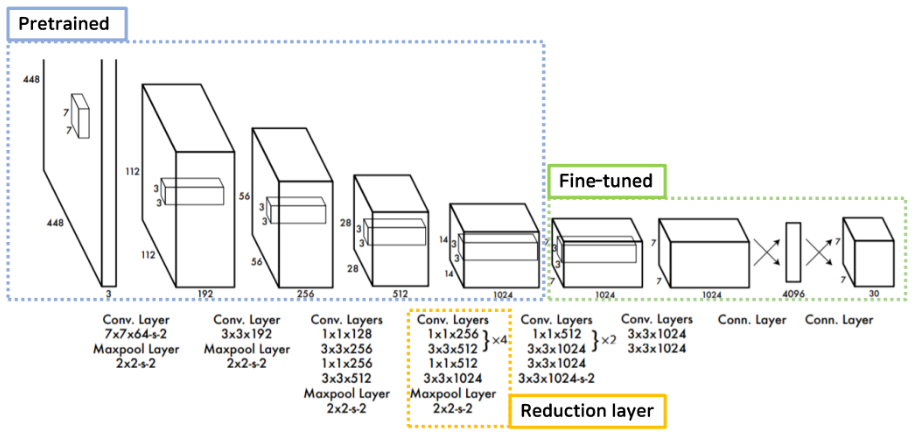

- Pretrained
The previous 20 conv layers were pretrained with 1000 classes of ImageNet datasets.
- Fine tuned
Four conv layers and two fc layers were added to the back and fine tuned with Pascal VOC data.
- Reduction layer
Reduce computation with 1x1 reduction layer
'Deep Learning > Object Detection' 카테고리의 다른 글
| YOLO(You Only Look Once) (0) | 2024.02.12 |
|---|---|
| (prerequisite-YOLO) One Stage Object Detection (0) | 2024.02.11 |
| Faster RCNN (0) | 2024.01.30 |
| Fast RCNN (0) | 2024.01.29 |
| (prerequisite-Fast R-CNN) Truncated SVD (0) | 2024.01.26 |