- Convolution(합성곱)
The step to get the result as below.
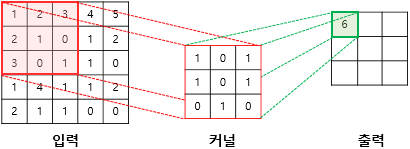
(1×1) + (2×0) + (3×1) + (2×1) + (1×0) + (0×1) + (3×0) + (0×1) + (1×0) = 6- image(입력)
- 3-dimension tensor, [height, width, channel].
- Height, width are the number of pixel.
- Kernel
The 2D matrix which has the size of
It usually (3 x 3) or (5 x 5).
- Steps
1. The kernel scans the image from the first to the end in order.
The image is scanned sequentially from the top left to the right.
2. While scanning, it multiplied by the elements from the image and kernel.
3. Sum all of them. The output(destination layer) is the feature map.
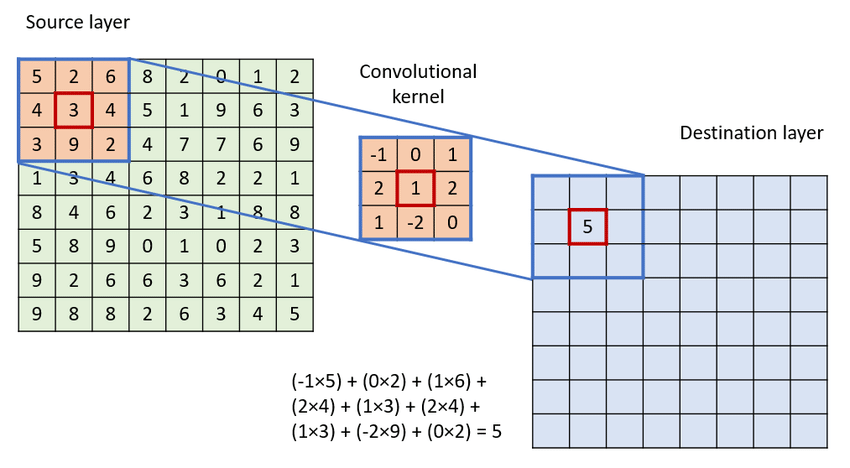
- Multiple filter convolution
When convolving a coloured image (RGB image) with channels 3, the channel of the filters must be 3 as well.In other words, in convolution, the number of channels in the kernel must be the same as the number of channels in the input image such as below.
| The number of channels in the input image == The number of channels in the kernel |
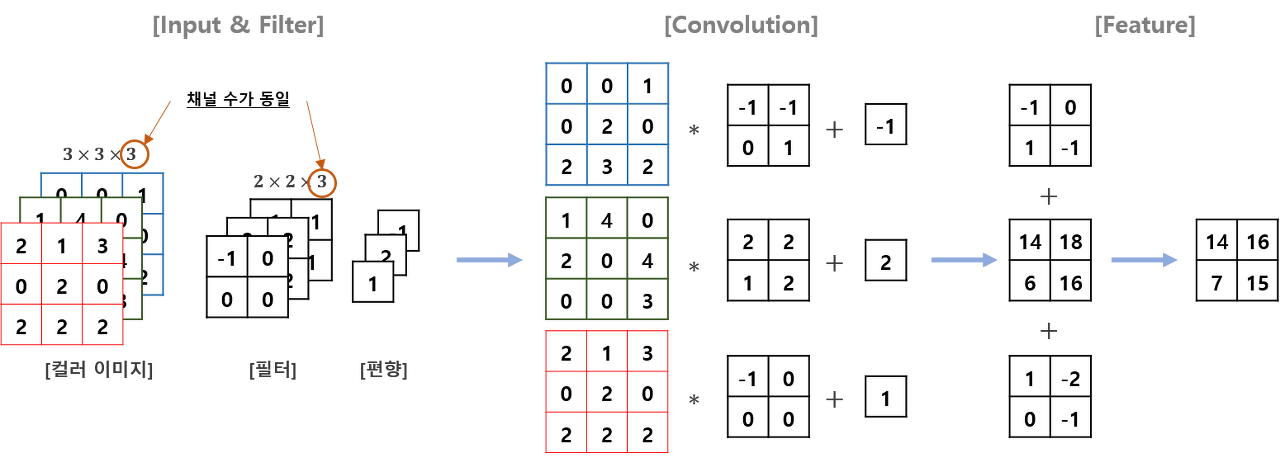
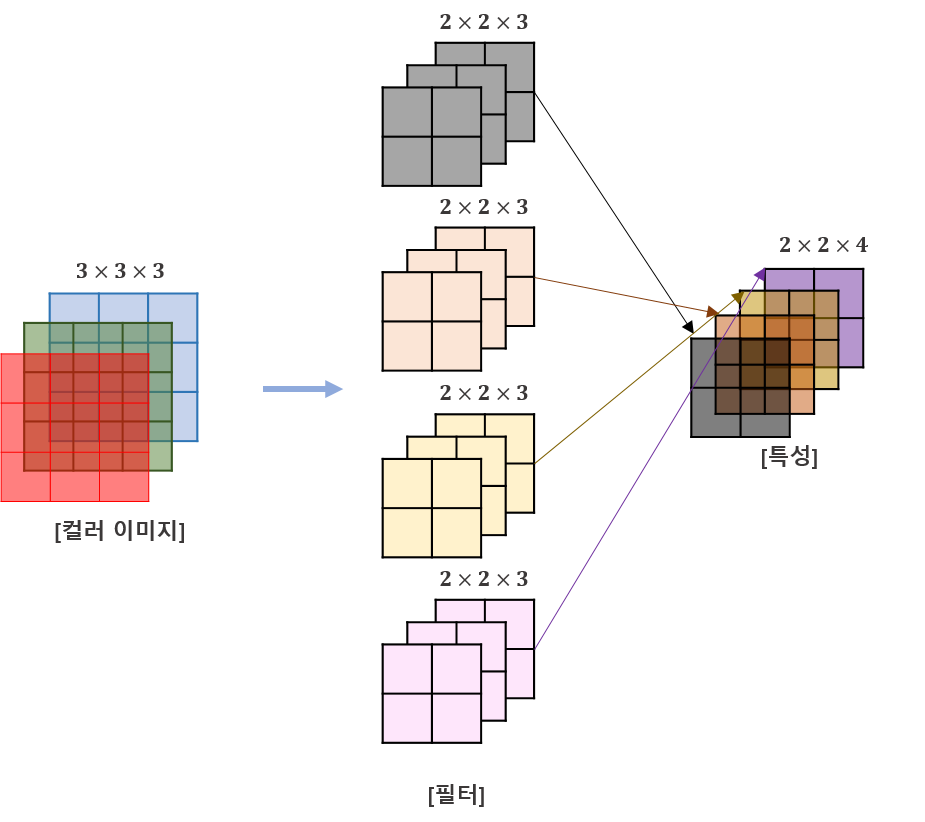
- Convolution Layer(합성곱층)

- Conv : Convolution operation
- Convolution Layer : It is responsible for extracting the feature map through the Convolution operation. The result of the convolution operation passes the activation function ReLU.
- channel (or depth)
Component of color.
Each pixel has between 1 and 255.
The channel of black image is 1.
The channel of color image is 3 which has Red, Green, Blue.
For example,

the image above is black, meaning the number of channel is 1.
3-dimension tensor which size is (28 × 28 × 1).
the image above is color, meaning the number of channel is 3.
3-dimension tensor which size is (28 × 28 × 3).
- filter
The filter dimensions are (channel x height x weight), 3D.
A concatenation of multiple kernels. Filters are always one dimension more than the kernels.
For example, in 2D convolutions, filters are 3D matrices.
- Kernel VS Filter

- Filter : Composed of several kernels
- Kernel : Individual kernels have different values within the filter
- Channel : The number of kernels
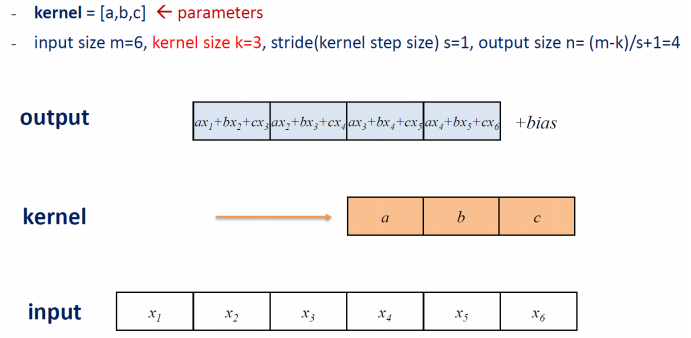
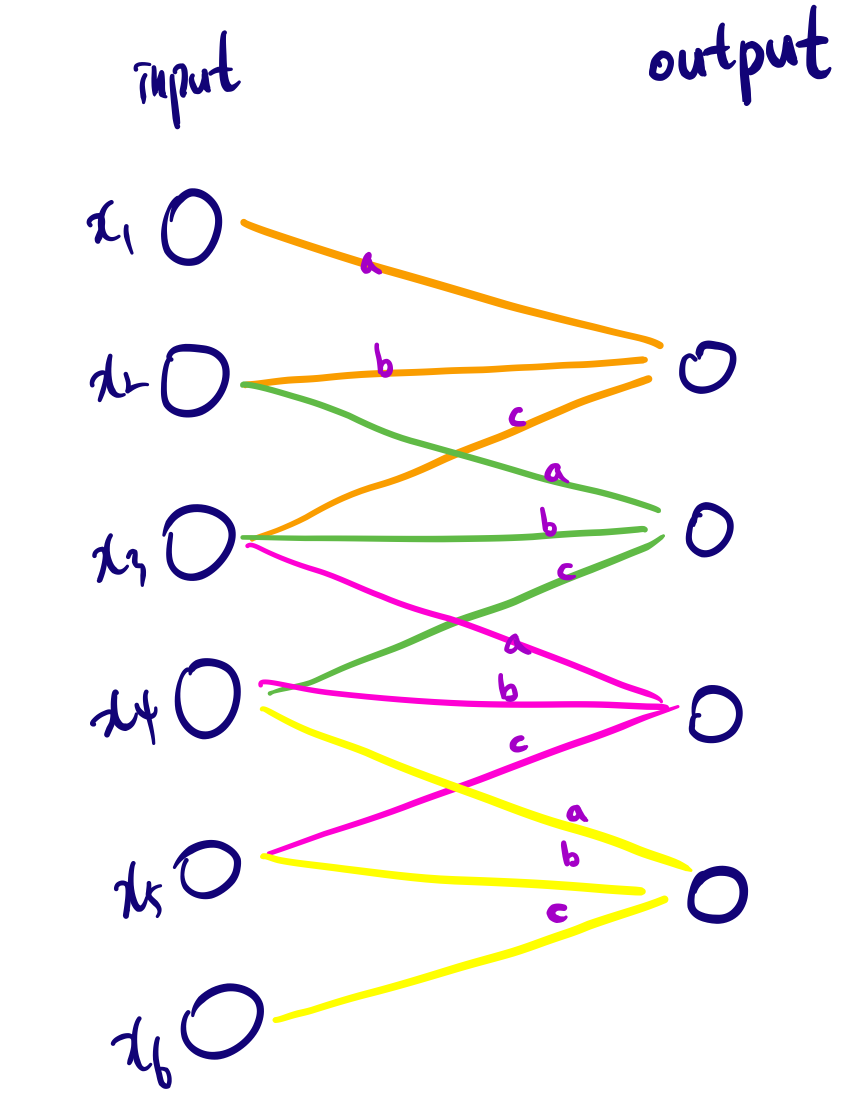
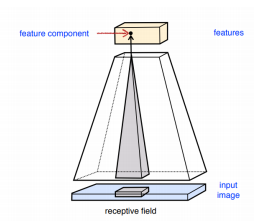
- Receptive field
The size of input(image) area that required to calculate a particular output node.
For example,
As shown in the figure below, 3 consecutive input nodes are required to calculate the value of each output node. In this case, the Receptive field size is 3.
- feature map
The output(destination layer) of Convolution.
It is characterized by being smaller size than input.
For example,
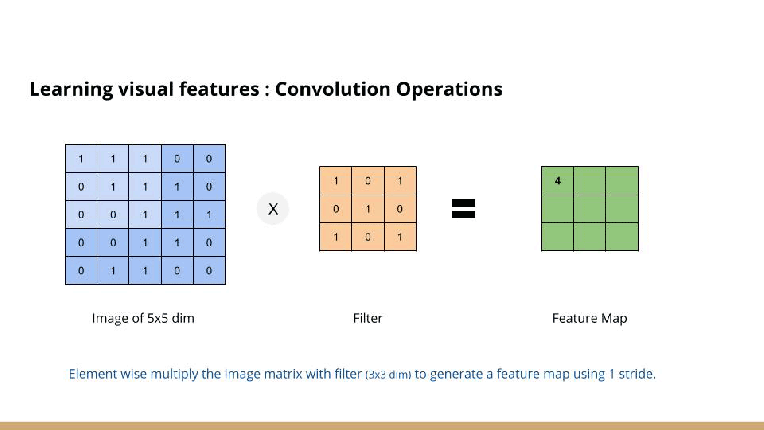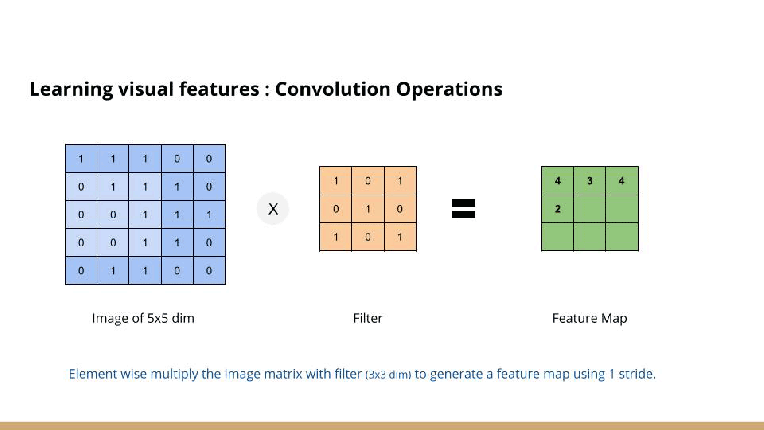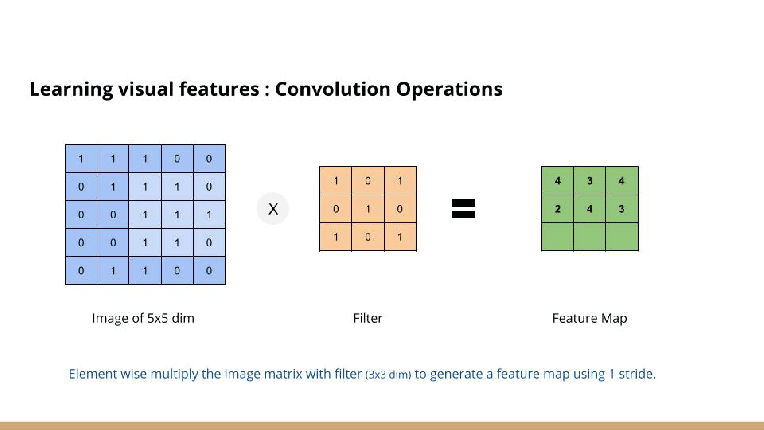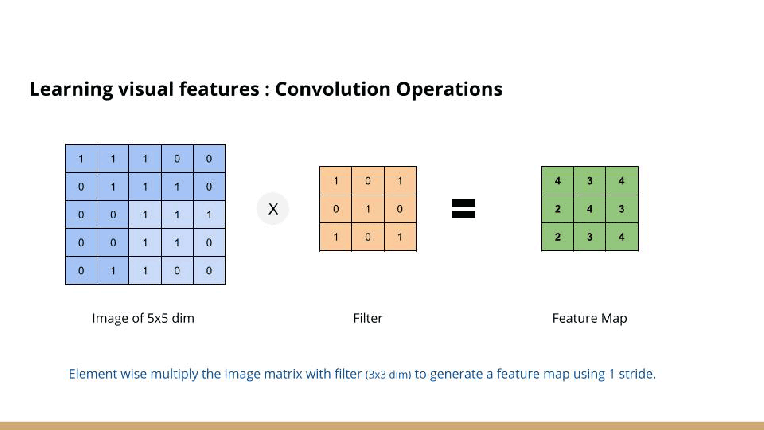
the image above is showing input image is (5 x 5), kernel is (3 x 3), output is (3 x 3).
The set of output nodes, the inputs which included in the Receptive field can be operated only in order to get the Feature Map.
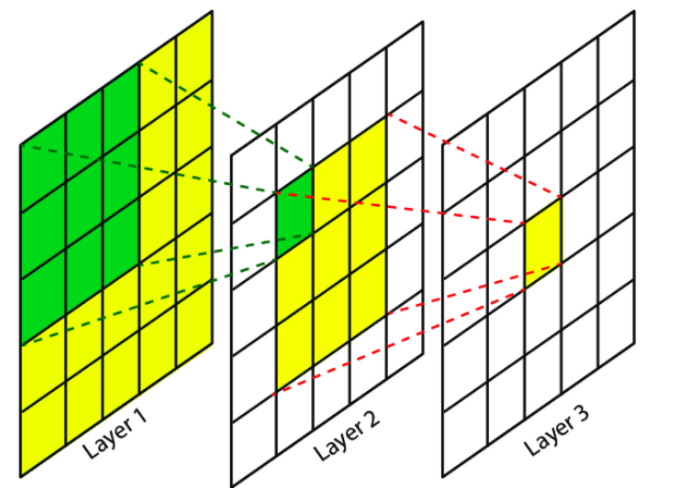
- How to increase the Receptive field
Increase kernel size or stack multiple layers.
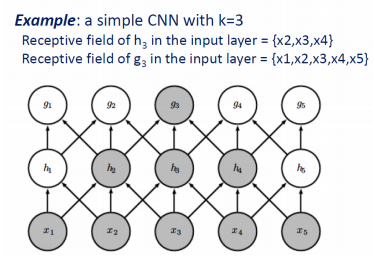
- Case 1. Increase kernel size
As shown in the figure below,
- The receptive field size of each h2, h3, h4 : 3
- The receptive field of g3 : x1, x2, x3, x4, x5
- The receptive field size of g3 : 5
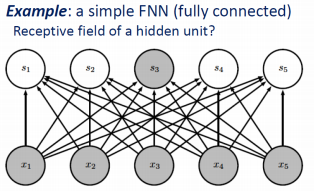
- Case 2. Stack multiple layers
Such as Fully Connected Dense Layer as below, The receptive field size of each nodes is 5.
- stride
Range of movement of the kernel, can be customized by user.
For example,
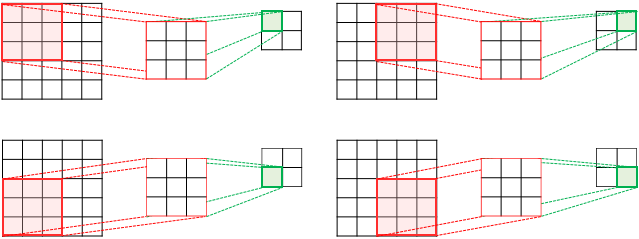
the image above is showing stride is 2, image size is (5 x 5), kernel size is (3 x 3), fature map size is (2 x 2).
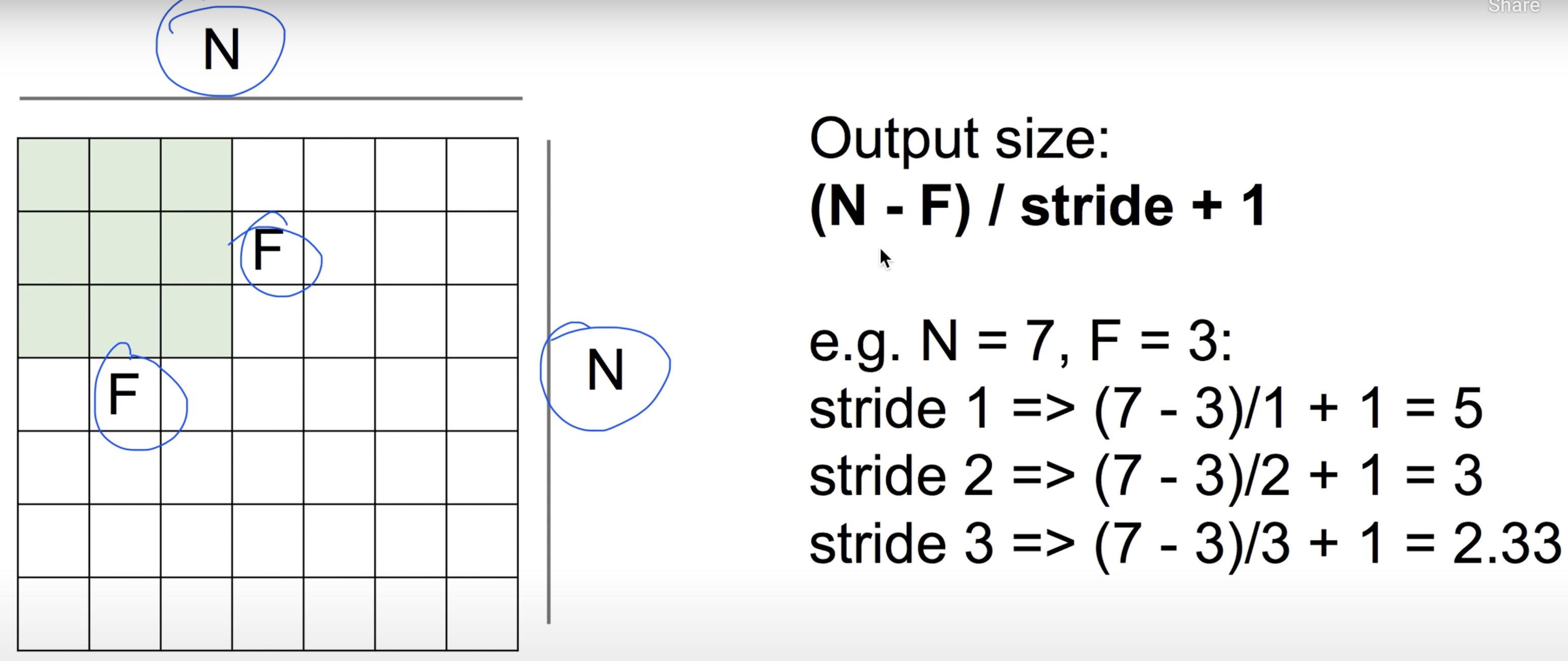
- How will be the output size after stride?
(Image size - Filter size) / Stride + 1
- padding
It an be the same size as the size of input using with padding.
- zero padding
For example,
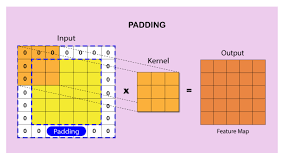
the image above is showing add 0 on the border.
If zero padding apply to
image size is (5 x 5), kernel size is (3 x 3), stride is 1,
then the size of feature map is same as image size(5 x 5).
- convolution layer
When we want to extract more than one feature from an image using convolution, we can use multiple kernels instead of using just one. In such a case, the size of all the kernels must be the same. The convolved features of the input image the output are stacked one after the other to create an output so that the number of channels is equal to the number of filters used. See the image below for reference.
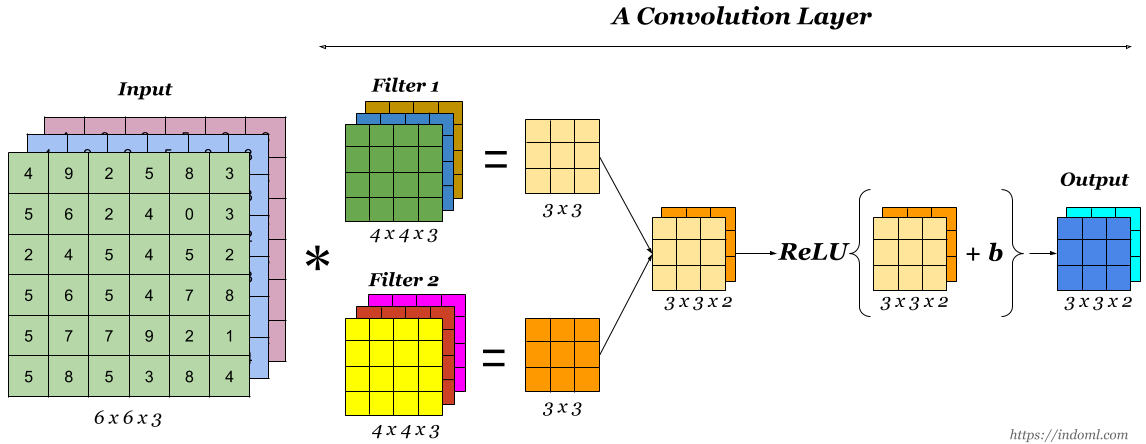
An activation function is the last component of the convolutional layer to increase the non-linearity in the output. Generally, ReLu function or Tanh function is used as an activation function in a convolution layer. Here is an image of a simple convolution layer, where a 6X6X3 input image is convolved with two kernels of size 4X4X3 to get a convolved feature of size 3X3X2, to which activation function is applied to get the output, which is also referred to as feature map.
- The feature map equation
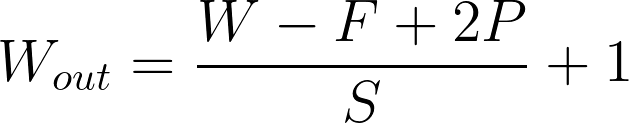 W : input width F : filter size P : padding S : stride |
- convolution layer bias
It can be added after kernel or filter applied.
- multiple kernels
If you use multiple kernels, the number of kernels is same as the number of feature map channels.
the number of kernels == the number of feature map channels.For example,
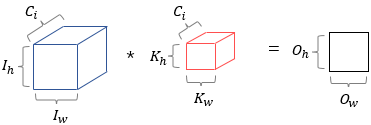
the image above is showing input data obtains a feature map, and channel 1.
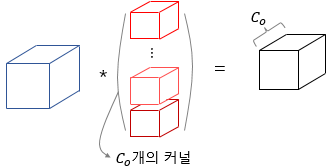
the image above is showing that if you use multiple kennels, the number of channels in the feature map are same.
- pooling
Nornally adding the pooling layer after convolution layer.
Pooling is mainly focuses on reducing the dimensions of the feature maps and downsampling an input image.
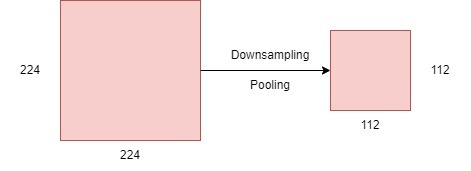
For example,
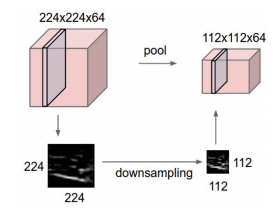
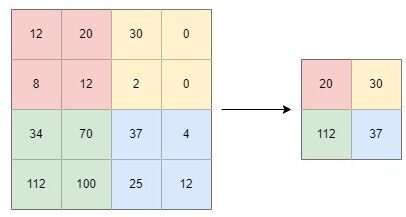
- max pooling
It computes the largest value in each windowed patch. The filter simply picks the maximum pixel value in the receptive field of the feature map.
- average pooling
It computes the average value in each windowed patch.

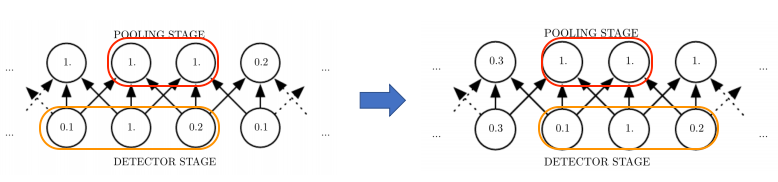
- Invariant to small translations of the input(Pooling)
The input does not change even if it is translated.
The strongest signal is the most significant. (Max Pooling)For example,
- Left of the picrue below : you can pick one of 3 of kernels.
- Right of the picrue below : Input was shifted(translated) to the right side.
- The result : There is no change(1., 1.) in the value of two node in the POOLING STAGE. Because pooling is picking a representative value from the local area, so even if it moves on the window, it becomes invariant.
'Deep Learning > CNN' 카테고리의 다른 글
| LeNet-5 (0) | 2024.01.04 |
|---|---|
| ResNet (0) | 2024.01.03 |
| AlexNet (0) | 2024.01.03 |
| VGG16 (0) | 2023.12.14 |
| (prerequisite-RoIs) Interpolation, Linear Interpolation, Bilinear Interpolation, ZOH(Zero-order Hold Interpolation) (0) | 2023.07.04 |