- Markov Decision Process
- Decision : Sequence of Actions.
- S1 : It absorbed S0, a0 to indicate a1.
- a1 : It is given by S1. If only S1 is given, a1 is determined regadless of S0, a0.

https://youtu.be/DbbcaspZATg?si=KgUq5CdJKzHj9QOJ
- Policy :
State, action are a pair.
- Return

In here,
- Goal of Reinforcement Learning :
Maximize Expected(Average) Return(Sum of rewards).
In order to do that, find the policy that can maximize the return.
- The way that express the Expected(Average) Return
1. State value function
The expected return from now.
What is the expected sum of rewards in the future due to being in this state at the moment?
Value of the current state.(Important is now, not the past)
Take all the actions for all states and add all the rewards.
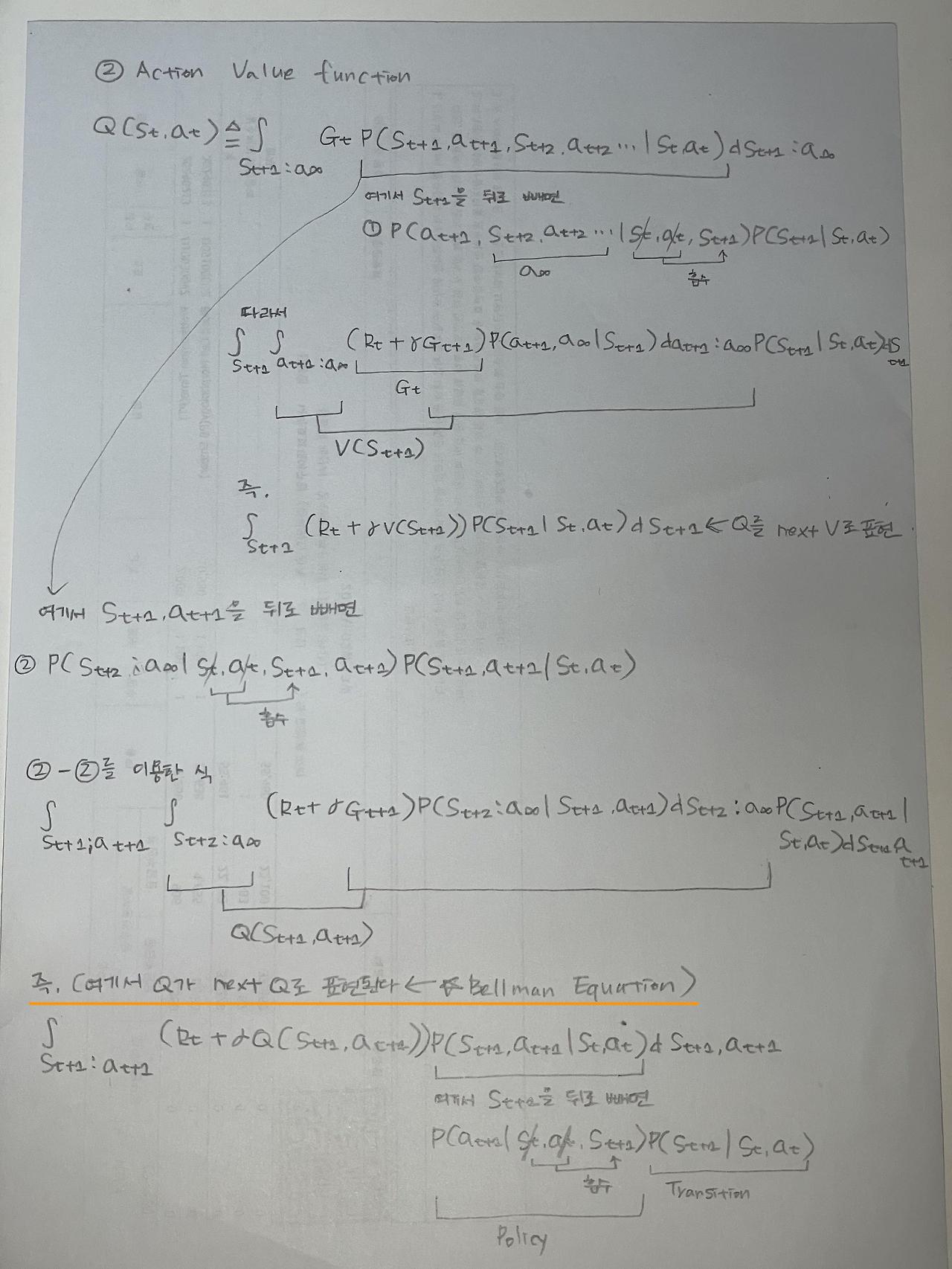
2. Action value function
The expected return from current action(Q-learning).
현재 상태에서 어떤 특정한 액션을 선택했을 때, 선택 후 받을 수 있는 (감마로 discounted가 된)리워드의 썸
https://youtu.be/7MdQ-UAhsxA?si=7nMOzl00vo6658H_
- Optimal policy
Maximize the State value function.


https://youtu.be/cn7IAfgPasE?si=Xp6C2bacSXXq9CnU
- Bellman equation

'Reinforcement Learning' 카테고리의 다른 글
| Behavior Policy VS Target Policy (0) | 2024.10.06 |
|---|---|
| Monte-carlo VS Temporal Difference (0) | 2024.10.06 |
| Q-Learning, Greedy action, Q-Value, Exploration, ϵ-greedy, epsilon-greedy, Exploitation, Discount factor, Q-update (0) | 2024.09.19 |