- ResNet

A 152-layer CNN architecture, which creates The Residual Blocks idea to address the issue of the vanishing/exploding gradient.
- Residual Block
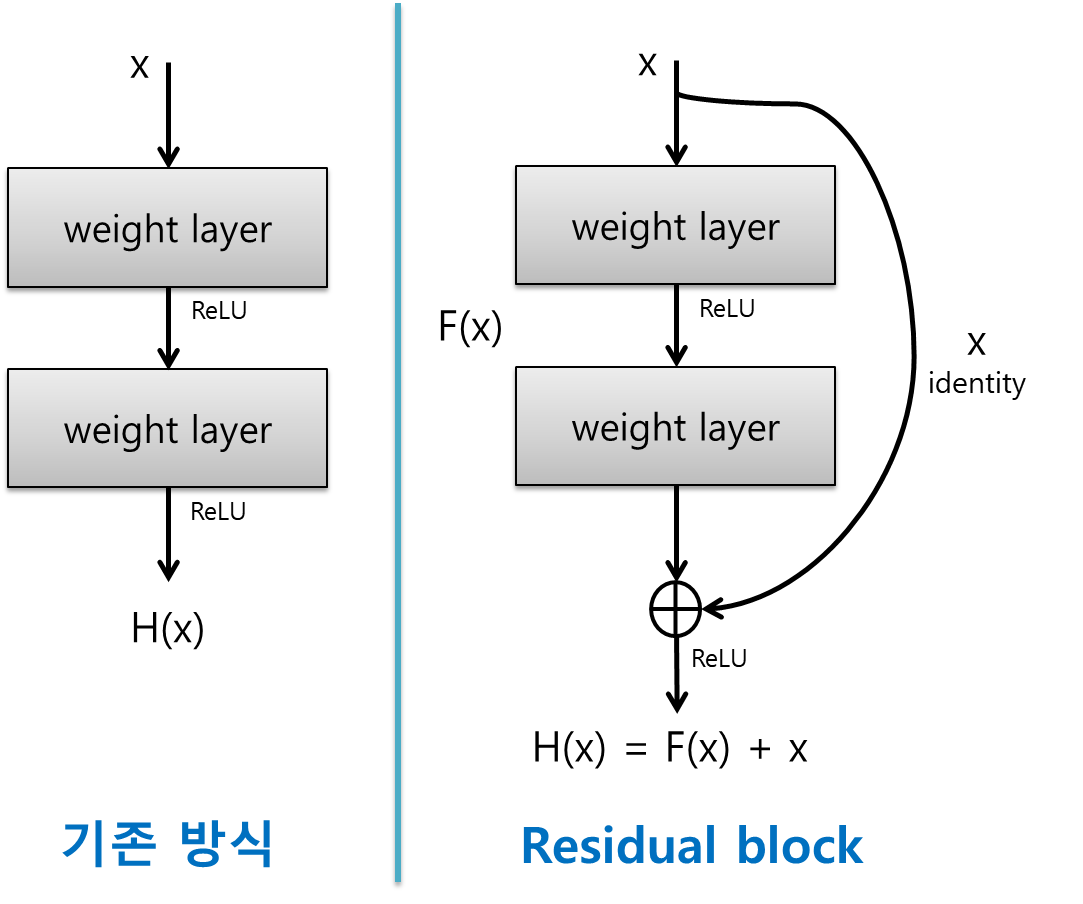
- Plane layer
y=f(x)
- Not add the input x
- y is Feature vector(Feature Map).
- y is the information newly learned through x.
- y is not preserve information when generate new information.
- The deeper the layers, too much mapping to learn at once.
- Residual Block
y=f(x)+x
- Add the input x after operation
- y preserves the previously learned information
- y is connecting the information learned in the previous layer to the output
- y allows each layer (Block) to learn only small information additionally(Reduce the amount of information each layer should learn).
- by adding the previously learned x, only the remaining part (F(X)) except for x is learned, so that the amount of learning is relatively reduced.
- Skip Connection
H(x)=F(x)+xis
F(x)=H(x)−x
- As the amount of learning increases, x gradually approaches the output value H(x)
- and the additional amount of learning F(x) gradually decreases and finally converges to a minimum value close to zero.
- Skip Connection allows the input value(x) to be added to the output by skipping certain layers.
https://velog.io/@lighthouse97/ResNet%EC%9D%98-%EC%9D%B4%ED%95%B4
https://medium.com/@siddheshb008/resnet-architecture-explained-47309ea9283d
- Residual of ResNet
H(x) - x
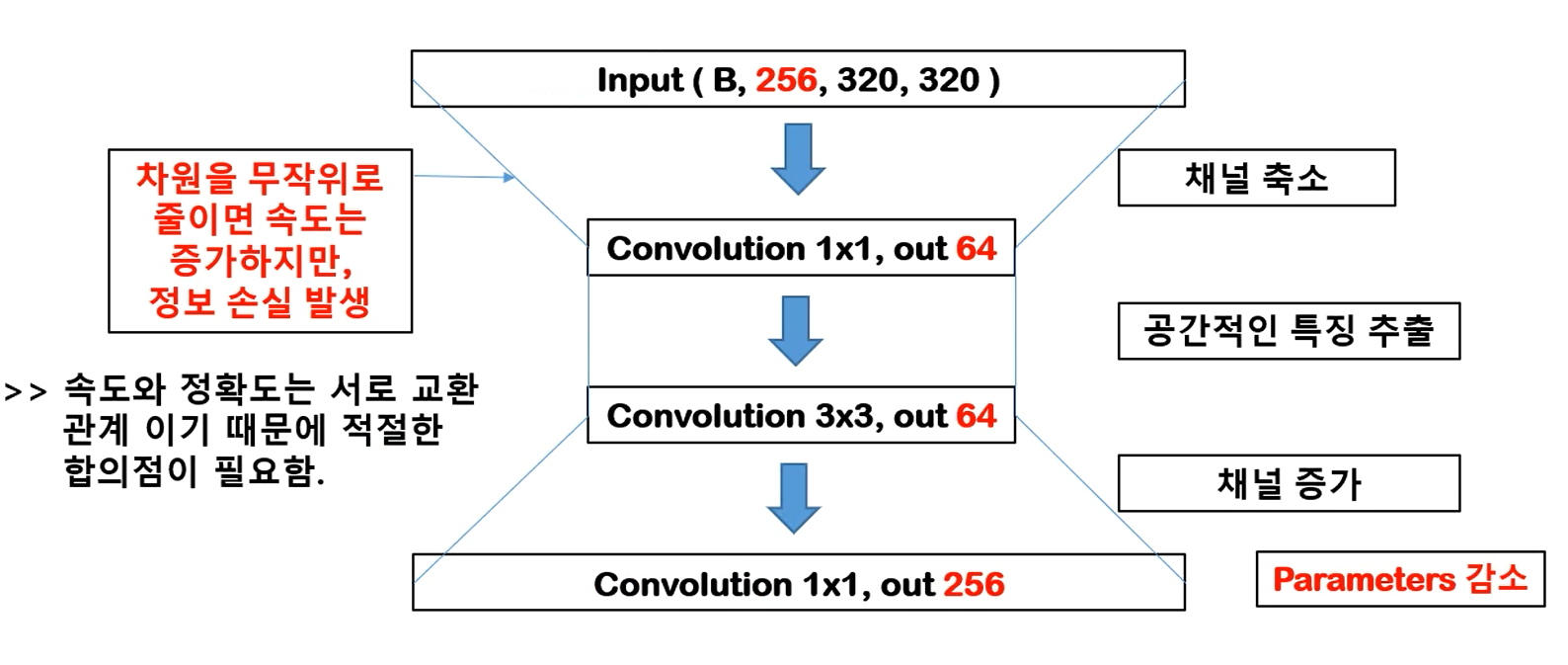
- Bottleneck
To reduce the calculation time. To reduce the dimension and then increase the dimension at the end.
'Deep Learning > CNN' 카테고리의 다른 글
| (prerequisite-CNN) Graph, Vertex(Node), Edge (0) | 2024.01.19 |
|---|---|
| LeNet-5 (0) | 2024.01.04 |
| AlexNet (0) | 2024.01.03 |
| VGG16 (0) | 2023.12.14 |
| (prerequisite-RoIs) Interpolation, Linear Interpolation, Bilinear Interpolation, ZOH(Zero-order Hold Interpolation) (0) | 2023.07.04 |