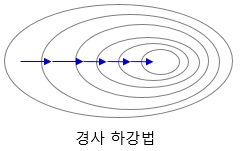
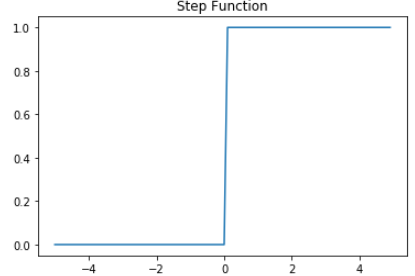
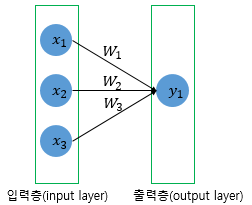
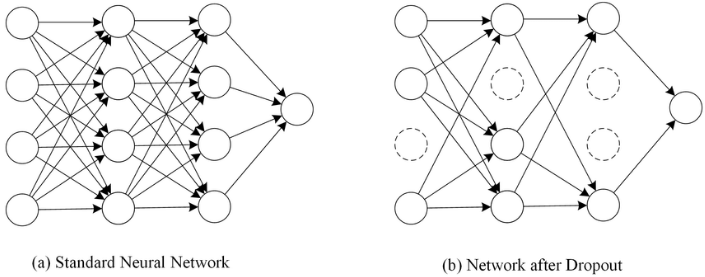
Loss function In deep learning, we typically use a gradient-based optimization strategy to train a model HTML 삽입 미리보기할 수 없는 소스 using some loss function HTML 삽입 미리보기할 수 없는 소스 are some input-output pair. It is used to help the model determine how "wrong" it is and, based on that "wrongness," improve itself. It's a measure of error. Our goal throughout training is to minimize this error/loss. https..