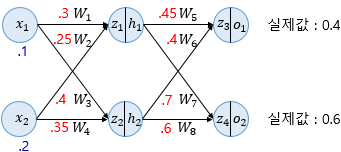
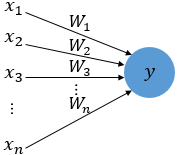
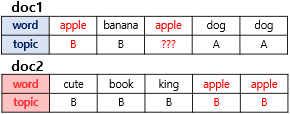
Forward Propagation Computation z : variable, accumulated sum from previous layers of x * w, before applied sigmoid(or whatever activation function) function z1=W1x1+W2x2=0.3×0.1+0.25×0.2=0.08z1=W1x1+W2x2=0.3×0.1+0.25×0.2=0.08 z2=W3x1+W4x2=0.4×0.1+0.35×0.2=0.11 Then, z1 and z2 shoulc through sigmoid(or whatever activation function) function in each hidden layer. h1=sigmoid(z1)=0.51998934h1=sigmo..