- LSA
Latent Semantic Analysis, substitute for DTM, TF-IDF(2021.03.10 - [Deep Learning] - BoW, CountVectorizer, fit_transform, vocabulary_, DTM, TDM, TF-IDF, TfidfVectorizer, isnull, fillna, pd.Series) which has not consider meaning of terms. It applies SVD based on DTM, TF-IDF and reduce dimensions, eliciting potential meaning of words.
1. SVD
Singular Value Decomposition, it refers to the decomposition of these 3 matrix when A is a matrix of m * n
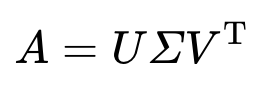
U : orthogonal matrix of m * m
∑ : diagonal matrix, all elements is zero except the main diagonal
V : orthogonal matrix of n * n
- Orthogonal matrix
The result of multiplication of transposed matrix or reverse transposed matrix should be identity matrix.
The matrix A should be satisfied all of below.

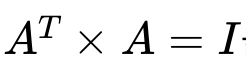
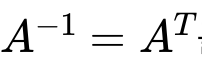
- Transposed matrix
The matrix transposed of row and column.

- Identity matrix
Square matrix, all elements is zero except the main diagonal which is 1.

- Inverse matrix
A matrix(A-1) makes identity matrix after multiply.

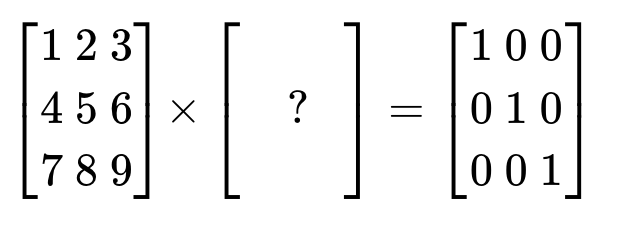
- Diagonal matrix
Rectangular matrix, all elements is zero except the main diagonal which is something.


import numpy as np
A=np.array([[0,0,0,1,0,1,1,0,0],[0,0,0,1,1,0,1,0,0],[0,1,1,0,2,0,0,0,0],[1,0,0,0,0,0,0,1,1]])
np.shape(A)
>>>
(4, 9)
U, s, VT=np.linalg.svd(A, full_matrices=True)
U.round(2)
>>>
array([[-0.24, 0.75, 0. , -0.62],
[-0.51, 0.44, -0. , 0.74],
[-0.83, -0.49, -0. , -0.27],
[-0. , -0. , 1. , 0. ]])
s.round(2)
>>>
array([2.69, 2.05, 1.73, 0.77])linalg.svd : It returns the eigenvalues and eigenvectors as a list.
full_matrices : If True, it returns square shape.
S=np.zeros((4,9))
S[:4,:4]=np.diag(s)
S
>>>
array([[2.68731789, 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. ],
[0. , 2.04508425, 0. , 0. , 0. ,
0. , 0. , 0. , 0. ],
[0. , 0. , 1.73205081, 0. , 0. ,
0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0.77197992, 0. ,
0. , 0. , 0. , 0. ]])numpy.diag : Extract a diagonal or construct a diagonal array.
This is Full SVD, U × S(=∑) × VT
np.dot(np.dot(U,S),VT).round(2)
>>>
array([[ 0., 0., 0., 1., 0., 1., 1., 0., 0.],
[ 0., -0., -0., 1., 1., -0., 1., -0., -0.],
[ 0., 1., 1., -0., 2., -0., -0., 0., 0.],
[ 1., -0., 0., 0., -0., 0., -0., 1., 1.]])
np.allclose(A,np.dot(np.dot(U,S),VT).round(2),equal_nan=True)
>>>
True
2. Truncated SVD
Dimensionality reduction, de-noising and compression rather than SVD.
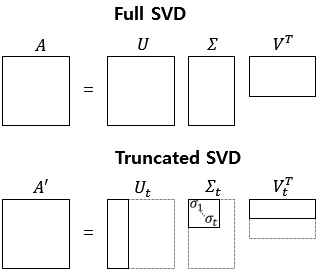
Let's assume t(hyperparameter) is 2, and then truncate by 2. This is Truncated SVD, Ut × S(=∑)t × VTt
S=S[:2,:2]
U=U[:,:2]
VT=(VT[:2,:])
A_prime=np.dot(np.dot(U,S),VT)
A_prime.round(2)
array([[ 0. , -0.17, -0.17, 1.07, 0.12, 0.63, 1.07, 0. , 0. ],
[ 0. , 0.2 , 0.2 , 0.91, 0.85, 0.46, 0.91, 0. , 0. ],
[ 0. , 0.93, 0.93, 0.04, 2.04, -0.17, 0.04, 0. , 0. ],
[ 0. , 0. , 0. , 0. , 0. , -0. , 0. , 0. , 0. ]])
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
dataset=fetch_20newsgroups(shuffle=True, random_state=1, remove=('headers','footers','quotes'))
document=dataset.data
news_df=pd.DataFrame({'document':document})
news_df.head()
>>>
document
0 Well i'm not sure about the story nad it did s...
1 \n\n\n\n\n\n\nYeah, do you expect people to re...
2 Although I realize that principle is not one o...
3 Notwithstanding all the legitimate fuss about ...
4 Well, I will have to change the scoring on my ...
news_df['clean_doc'] = news_df['document'].str.replace("[^a-zA-Z]", " ")
news_df['clean_doc'] = news_df['clean_doc'].apply(lambda x: ' '.join([w for w in x.split() if len(w)>3]))
news_df['clean_doc'] = news_df['clean_doc'].apply(lambda x: x.lower())
from nltk.corpus import stopwords
import nltk
nltk.download('stopwords')
tokenized = news_df['clean_doc'].apply(lambda x:x.split())
stop_words=set(stopwords.words('english'))
tokenized=tokenized.apply(lambda x: [i for i in x if i not in stop_words])
detoken=[]
for i in range(len(news_df)):
t=' '.join(tokenized[i])
detoken.append(t)
news_df['clean_doc']=detoken
news_df['clean_doc'][1]
>>>
yeah expect people read actually accept hard atheism need little leap faith jimmy logic runs steam sorry pity sorry feelings denial faith need well pretend happily ever anyway maybe start newsgroup atheist hard bummin much forget flintstone chewables bake timmons
from sklearn.feature_extraction.text import TfidfVectorizer
vec=TfidfVectorizer(stop_words='english',max_features=1000,max_df=0.5, smooth_idf=True)
X=vec.fit_transform(news_df['clean_doc'])
from sklearn.decomposition import TruncatedSVD
svd_model=TruncatedSVD(n_components=20, algorithm='randomized',n_iter=10, random_state=10)
svd_model.fit(X)
terms=vec.get_feature_names()
def get_topics(components, feature_names,n=5):
for idx,topic in enumerate(components):
print('Topic %d:'%(idx+1), [(feature_names[i],topic[i].round(5)) for i in topic.argsort()[:-n-1:-1]])
get_topics(svd_model.components_,terms)
>>>
Topic 1: [('like', 0.21386), ('know', 0.20046), ('people', 0.19293), ('think', 0.17805), ('good', 0.15128)]
Topic 2: [('thanks', 0.32888), ('windows', 0.29088), ('card', 0.18069), ('drive', 0.17455), ('mail', 0.15111)]
...max_features : Adjust the number of feature(number of words), for example, if average lenght of row is 10 but one row has over 100, then it needs to be adjusted to 10
max_df or min_df: Maximum Document Frequency, the threshold that the token can be ignored if the frequency is over max_df or less than min_df.
Integer or a number between 0.0 and 1.0, default is 1
smooth_idf : Smooth Inverse Document Frequency, it defines whether add small value or no when adjust the feature when the element of feature is 0.
fit_transform(X) : Fit model to X and perform dimensionality reduction on X.
n_components : Number of Components, desired dimensionality of output data
algorithm : SVD solver to use
- randomized : default, easier to efficiently parallelize and makes fewer passes over the data, magnitude faster.
n_iter : Number of Iterations for randomized SVD solver
random_state : It applies to get the same result, i.g., unless random_state applies it, TruncatedSVD function extracts different data whenever it implements but if random_state applied, TruncatedSVD function extracts same data even if function implements many times.
fit(X) : Fit model on training data X.
3. LDA
Latent Ditichlet Allocation, is a process to find the topic(hidden meaning) from the set of documents. It is used to classify text in a document to a particular topic.
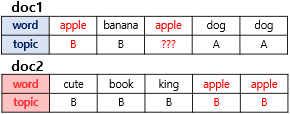
- The first criterion is observe which topic is belong the words in doc1, following this criterion, it is high chance 'apple' belongs to both of topic A and B because topic A and B are allocated same proportion.
- The second criterion is observe 'apple' in which topic is belong to. According to this criterion, it is high chance to allocates to topic B.
from gensim import corpora
Dict=corpora.Dictionary(tok_doc)
corpus=[Dict.doc2bow(text) for text in tok_doc]
Dict[33]
>>>races
import gensim
NUM_TOPICS=20
ldamodel=gensim.models.ldamodel.LdaModel(corpus, num_topics=NUM_TOPICS, id2word=Dict, passes=15)
topics=ldamodel.print_topics(num_words=4)
for topic in topics:
print(topic)
>>>(0, '0.007*"people" + 0.007*"government" + 0.006*"president" + 0.006*"would"')
(1, '0.011*"would" + 0.007*"like" + 0.006*"used" + 0.006*"system"')
(2, '0.010*"homosexual" + 0.007*"sexual" + 0.007*"homosexuals" + 0.007*"cramer"')
(3, '0.009*"nrhj" + 0.006*"wwiz" + 0.005*"bxom" + 0.005*"gizw"')
(4, '0.011*"available" + 0.010*"information" + 0.009*"mail" + 0.009*"software"')
(5, '0.009*"writes" + 0.008*"smith" + 0.007*"john" + 0.006*"article"')
(6, '0.023*"israel" + 0.016*"jews" + 0.015*"israeli" + 0.009*"arab"')
(7, '0.018*"turkish" + 0.012*"turkey" + 0.009*"turks" + 0.009*"fire"')
(8, '0.025*"space" + 0.013*"nasa" + 0.006*"ground" + 0.005*"launch"')
(9, '0.013*"jesus" + 0.008*"people" + 0.008*"said" + 0.006*"armenian"')
(10, '0.021*"writes" + 0.018*"article" + 0.008*"braves" + 0.006*"morris"')
(11, '0.011*"would" + 0.011*"like" + 0.010*"writes" + 0.009*"article"')
(12, '0.014*"game" + 0.014*"team" + 0.011*"year" + 0.010*"games"')
(13, '0.018*"windows" + 0.013*"thanks" + 0.012*"know" + 0.012*"anyone"')
(14, '0.013*"writes" + 0.011*"article" + 0.010*"bike" + 0.007*"period"')
(15, '0.023*"file" + 0.014*"window" + 0.013*"program" + 0.010*"entry"')
(16, '0.011*"encryption" + 0.011*"government" + 0.010*"chip" + 0.009*"clipper"')
(17, '0.023*"drive" + 0.013*"scsi" + 0.010*"disk" + 0.009*"hard"')
(18, '0.012*"would" + 0.012*"people" + 0.011*"writes" + 0.010*"think"')
(19, '0.005*"crypt" + 0.005*"judges" + 0.005*"public" + 0.004*"liar"')
for i,topic_list in enumerate(ldamodel[corpus]):
if i==5:
break
print(i,topic_list)
>>>0 [(6, 0.26067126), (9, 0.11920204), (11, 0.47745645), (18, 0.129767)]
1 [(1, 0.034134515), (6, 0.044855535), (7, 0.14990851), (11, 0.25653347), (17, 0.035405792), (18, 0.47377756)]
2 [(6, 0.51913553), (11, 0.34204835), (18, 0.12510644)]
3 [(8, 0.035031598), (9, 0.080692686), (11, 0.06660855), (14, 0.10093034), (16, 0.4430262), (17, 0.07132838), (18, 0.19268075)]
4 [(9, 0.24132627), (12, 0.72534037)]
def topictable(ldamodel, corpus):
t_t=pd.DataFrame()
for i,topic_list in enumerate(ldamodel[corpus]):
doc=topic_list[0] if ldamodel.per_word_topics else topic_list
doc=sorted(doc, key=lambda x:(x[1]), reverse=True)
for j,(t_n,p_t) in enumerate(doc):
if j==0:
t_t=t_t.append(pd.Series([int(t_n), round(p_t,4), topic_list]), ignore_index=True)
else:
break
return t_t
tt=topictable(ldamodel, corpus)
tt=tt.reset_index()
tt.columns=['num','high prop topic','highest topic prop','each topic prop']
tt[:3]
>>>
num high prop topic highest topic prop each topic prop
0 0 11.0 0.4775 [(6, 0.2606831), (9, 0.11921346), (11, 0.47749...
1 1 18.0 0.4738 [(1, 0.034125905), (6, 0.044855397), (7, 0.149...
2 2 6.0 0.5191 [(6, 0.5191248), (11, 0.3419658), (18, 0.12519...
Each number in front of word(example, '0.007*"people") is word contribution to its topic.
corpora.Dictionary() : dictionary encapsulates the mapping between normalized words and their integer ids. It is used to construct sparse Bag-Of-Word vectors.
gensim.models.ldamodel.LdaModel(num_topics=) : the number of requested latent topics to be extracted from the training corpus.
gensim.models.ldamodel.LdaModel(id2word=) : mapping from word IDs to words.
gensim.models.ldamodel.LdaModel(passes=) : the number of algorithm running
ldamodel.print_topics() : get the most significant topics
ldamodel.print_topics(num_words=) : the number of words to be included per topics(ordered by signivicance)
ldamodel.per_word_topics : boolean, if true, the model also computes a list of topics, sorted in descending order of most likely topics for each word, along with their phi values multiplied by the feature length.
append(ingnore_index=True) : append rows of other to the end of caller. default false.
df=pd.DataFrame([[1,2],[3,4]],columns=list('ab'))
df2=pd.DataFrame([[5,6],[7,8]],columns=list('ab'))
df.append(df2)
>>>
a b
0 1 2
1 3 4
0 5 6
1 7 8
df.append(df2, ignore_index=True)
>>>
a b
0 1 2
1 3 4
2 5 6
3 7 8
import urllib.request
urllib.request.urlretrieve("https://raw.githubusercontent.com/franciscadias/data/master/abcnews-date-text.csv", filename="abcnews-date-text.csv")
data=pd.read_csv("abcnews-date-text.csv", error_bad_lines=False)
text=data[['headline_text']]
import nltk
text['headline_text']=text.apply(lambda row:nltk.word_tokenize(row['headline_text']),axis=1)
text=text[:1000]
from nltk.corpus import stopwords
stop=stopwords.words('english')
text['headline_text']=text.apply(lambda x:[word for word in x if word not in (stop)])
text.head()
>>>
headline_text
0 [aba, decides, against, community, broadcastin...
1 [act, fire, witnesses, must, be, aware, of, de...
2 [a, g, calls, for, infrastructure, protection,...
3 [air, nz, staff, in, aust, strike, for, pay, r...
4 [air, nz, strike, to, affect, australian, trav...
from nltk.stem import WordNetLemmatizer
text['headline_text']=text['headline_text'].apply(lambda x:[WordNetLemmatizer().lemmatize(word, pos='v') for word in x])
morethan3=text['headline_text'].apply(lambda x:[word for word in x if len(word)>3])
detoken=[]
for i in range(len(text)):
t=' '.join(morethan3[i])
detoken.append(t)
text['headline_text']=detoken
text['headline_text'].head()
>>>
0 decide against community broadcast licence
1 fire witness must aware defamation
2 call infrastructure protection summit
3 staff aust strike rise
4 strike affect australian travellers
Name: headline_text, dtype: object
from sklearn.feature_extraction.text import TfidfVectorizer
tv=TfidfVectorizer(stop_words='english', max_features=100)
X=tv.fit_transform(text['headline_text'])
from sklearn.decomposition import LatentDirichletAllocation
lda_model=LatentDirichletAllocation(n_components=10, learning_method='online', random_state=77,max_iter=1)
X_model=lda_model.fit_transform(X)
print(lda_model.components_.shape)
>>>
(10, 100)
terms=tv.get_feature_names()
def get_topics(components, feature_names,n=5):
for idx,topic in enumerate(components):
print('topic %d:'%(idx+1), [(feature_names[i], topic[i].round(2)) for i in topic.argsort()[:-n-1:-1]])
get_topics(lda_model.components_,terms)
>>>
topic 1: [('record', 7.48), ('lead', 7.38), ('club', 5.86), ('action', 5.57), ('attack', 5.48)]
topic 2: [('police', 12.91), ('rain', 6.89), ('jail', 6.48), ('offer', 6.14), ('kill', 5.65)]
topic 3: [('claim', 12.03), ('talk', 7.39), ('iraqi', 7.27), ('race', 7.26), ('defend', 6.11)]
topic 4: [('court', 11.27), ('murder', 8.14), ('face', 7.36), ('drought', 7.01), ('price', 6.19)]
topic 5: [('iraq', 12.44), ('water', 8.92), ('warn', 6.95), ('expect', 6.17), ('death', 6.08)]
topic 6: [('warne', 7.55), ('continue', 7.27), ('charge', 6.98), ('coast', 6.11), ('turkey', 5.91)]
topic 7: [('report', 6.68), ('anti', 6.28), ('make', 5.48), ('zimbabwe', 5.44), ('seek', 5.1)]
topic 8: [('break', 6.42), ('stay', 4.94), ('patterson', 4.63), ('raid', 4.17), ('health', 3.98)]
topic 9: [('council', 9.84), ('govt', 7.74), ('aust', 4.53), ('cost', 4.44), ('decision', 3.68)]
topic 10: [('plan', 16.21), ('match', 5.59), ('urge', 5.52), ('england', 5.39), ('community', 4.75)]pd.read_csv(error_bad_lines=) : boolean, lines with too many fields(e.g. a csv line with too many commas) will by default cause an exception to be raised, and no DataFrame will be returned. If False, then these 'bad lines'will dropped from the DataFrame that is returned.
dataframe.apply() : apply a function along an axis of the DataFrame
- axis=0 or 'index' : apply function to each column
- axis=1 or 'columns' : apply function to each row
df=pd.DataFrame([[1,2],[3,4]],columns=list('ab'))
df
>>>
a b
0 1 2
1 3 4
df.apply(np.sqrt)
>>>
a b
0 1.000000 1.414214
1 1.732051 2.000000
df.apply(np.sum, axis=0)
>>>
a 4
b 6
dtype: int64
df.apply(np.sum, axis=1)
>>>
0 3
1 7
dtype: int64
LatentDirichletAllocation(n_components=) : number of topics.
LatentDirichletAllocation(learning_method=) : there are two-'batch', 'online'-if the size is large, the 'online' will be much faster than the batch update.
LatentDirichletAllocation(random_state=) : pass an int for reproducible results across multiple function calls.
LatentDirichletAllocation(max_iter=) :the maximum number of iterations, default is 10
LatentDirichletAllocation.components_ : It can be viewed as distribution over the words for each topic after normalization
'Deep Learning' 카테고리의 다른 글
| FFNN, RNN, FCNNs (0) | 2021.04.05 |
|---|---|
| Perceptron, Step function, Single-Layer Perceptron, Multi-Layer Perceptron, DNN (0) | 2021.03.31 |
| Bag of words(BoW), DTM, TDM, TF-IDF (0) | 2021.03.10 |
| LM, Language Model, Language Modeling, Conditional Probability, Statistical Language Model, n-gram (0) | 2021.03.09 |
| normalization, WordNetLemmatizer, PorterStemmer, LancasterStemmer, Storword (0) | 2021.03.05 |