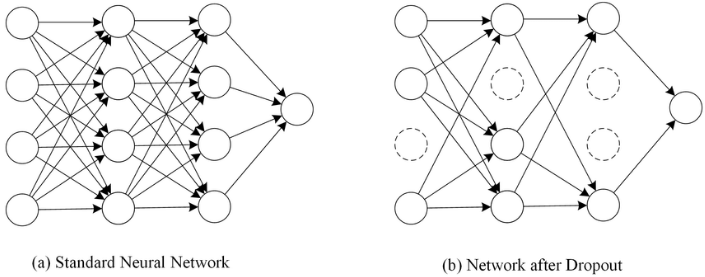
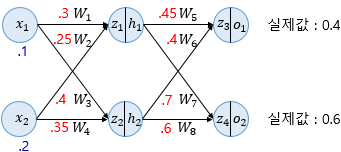
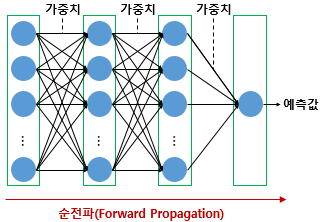
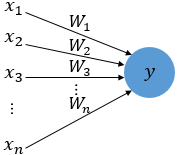
Dropout - One way to avoid overfitting, using several neurons only rather than whole neurons when machine training.- It does not have any learnable parameters and has only one hyperparameter.- It does not behave similarly during training and testing. To be understand this, let us consider a simple fully connected layer containing 10 neurons. We are using a dropout probability of 0.5. Well durin..