- Jaro-Winkler distance
- One of edit distance based algorithms which is falling under this category try to compute the number of operations needed to transforms one string to another. More the number of operations, less is the similarity between the two strings. One point to note, in this case, every index character of the string is given equal importance.
- It uses a prefix scale p which gives more favorable ratings to strings that match from the beginning for a set prefix length l.
Reference : medium.com/@appaloosastore/string-similarity-algorithms-compared-3f7b4d12f0ff
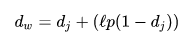
p is a constant scaling factor for how much the score is adjusted upwards for having common prefixes. The standard value for this constant in Winkler’s work is p=0.1.
l is the length of common prefix at the start of the string (up to a maximum of 4 characters).
So back to the “martha”/ “marhta” example(
2021/02/26 - [Machine Learning] - Jaro distance, from __future__, def main(), __name__), let’s take a prefix lenght of l = 3 (which refers to “mar”). We get to:
dw = 0,944 + ( (0,1*3)(1–0,944)) = 0,944 + 0,3*0,056 = 0,961
Jaro-Winkler distance = 96,1%def jaro_distance(s1,s2):
if (s1==s2):
return 1.0
len1=len(s1)
len2=len(s2)
if (len1==0 or len2==0):
return 0.0
max_dist=(max(len1, len2)//2)-1
match=0
hash_s1=[0]*len1
hash_s2=[0]*len2
for i in range(len1):
for j in range(max(1,i-max_dist),min(len2, i+max_dist+1)):
if (s1[i]==s2[j] and hash_s2[j]==0):
hash_s1[i]==1
hash_s2[j]==1
match+=1
break
if (match==0):
return 0.0
t=0
point=0
for i in range(len1):
if (hash_s1[i]):
while (hash_s2[point]==0):
point+=1
if (s1[i]!=s2[point]):
point+=1
t+=1
else:
point+=1
# global t
t/=2
return ((match/len1+match/len2+(match-t)/match)/3.0)
def jaro_Winkler(s1,s2):
jaro_dist=jaro_distance(s1,s2)
len1=len(s1)
len2=len(s2)
if (jaro_dist>0.7):
prefix=0;
for i in range(min(len1, len2)):
if (s1[i]==s2[i]):
prefix+=1
else:
break
prefix=min(4,prefix)
jaro_dist+=0.1*prefix*(1-jaro_dist)
return jaro_dist
# if __name__=='__main__':
# s1='TRATE'
# s2='TRACE'
# print(jaro_Winkler(s1,s2))
s1 = "TRATE"
s2 = "TRACE"
print(jaro_Winkler(s1, s2))
>>>0.8133333333333334
- Python Jaro-Winkler package
import textdistance
textdistance.jaro_winkler('apple', 'APPLE.')
>>>0.0
textdistance.jaro_winkler('apple', 'aple.')
>>>0.8933333333333333
textdistance.jaro_winkler('apple', 'pple')
>>>0.9333333333333332
textdistance.jaro_winkler('apple', 'elppa')
>>>0.6In first case, type of character is dissimilar, small characters and capital characers, which resulted in 0% similarity.
In second case, as the strings were matching from the beginning, high score was provided. Similarly, in the third case, only one character was missing and that too at the beginning of the string 2, hence a very high score was given.
In fourth case, I re-arrangeed the characters of string 2 by reverse, which resulted in 60% similarity.
Reference : itnext.io/string-similarity-the-basic-know-your-algorithms-guide-3de3d7346227
'Analyze Data > Measure of similarity' 카테고리의 다른 글
| Vector Similarity-2. Euclidean distance (0) | 2021.03.03 |
|---|---|
| Vector Similarity-7. Sørensen similarity (0) | 2021.03.02 |
| Vector Similarity-3. Jaccard Similarity (0) | 2021.03.02 |
| Vector Similarity-5. Jaro distance (0) | 2021.02.26 |
| Vector Similarity-4. Levenshtein distance (0) | 2021.02.25 |