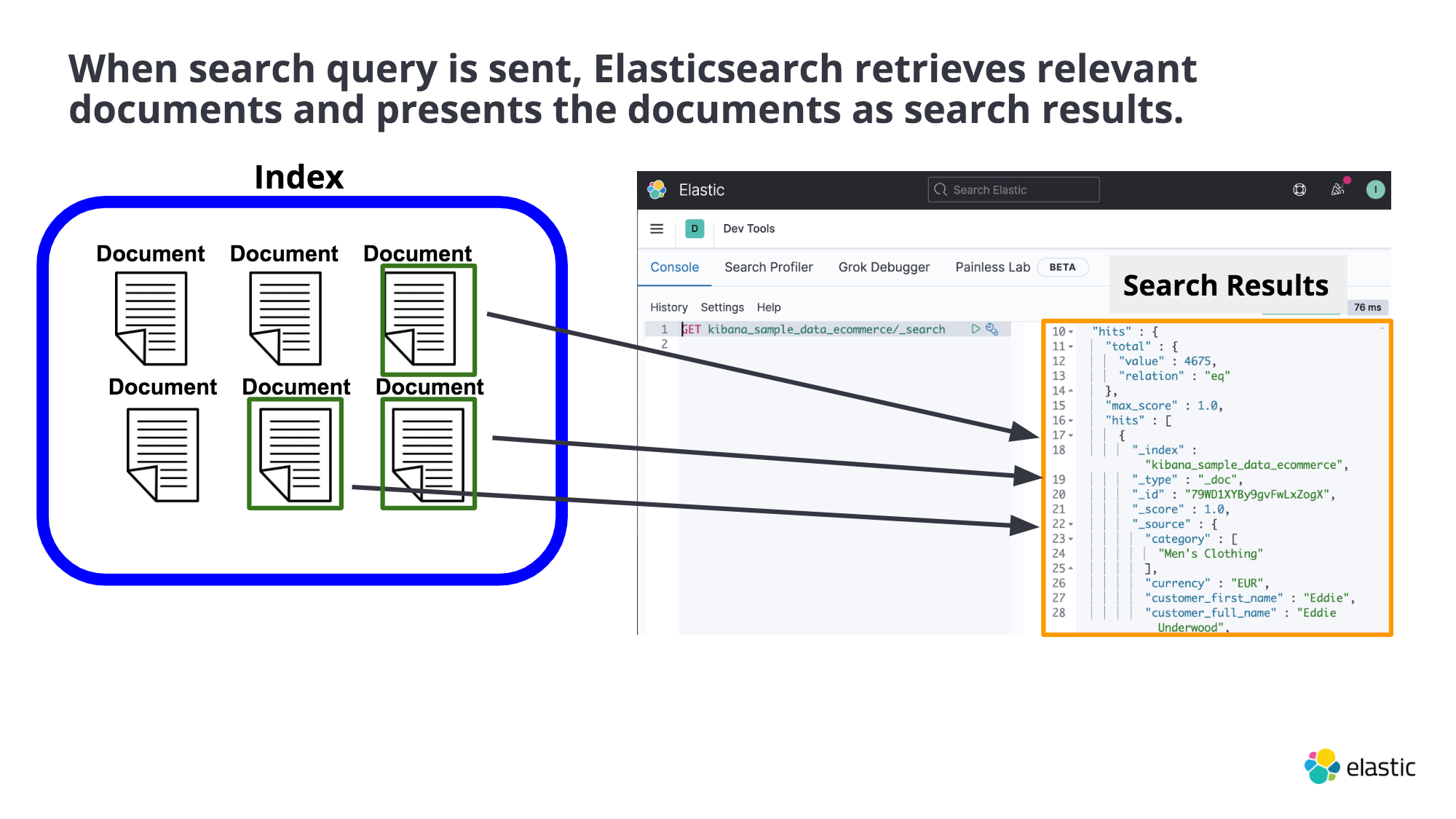
Document : Data is stored as document that share similar traits are grouped into an index. User ↓ ⇢ search something Elasticsearch ↓ ⇢ retrieves relevant documents, then Elasticsearch presents them as search results Search Results Precision : The dots inside the white circle, the portion of the retrived data actually relevant to the search query. All the retrived results to be a perfect match to..