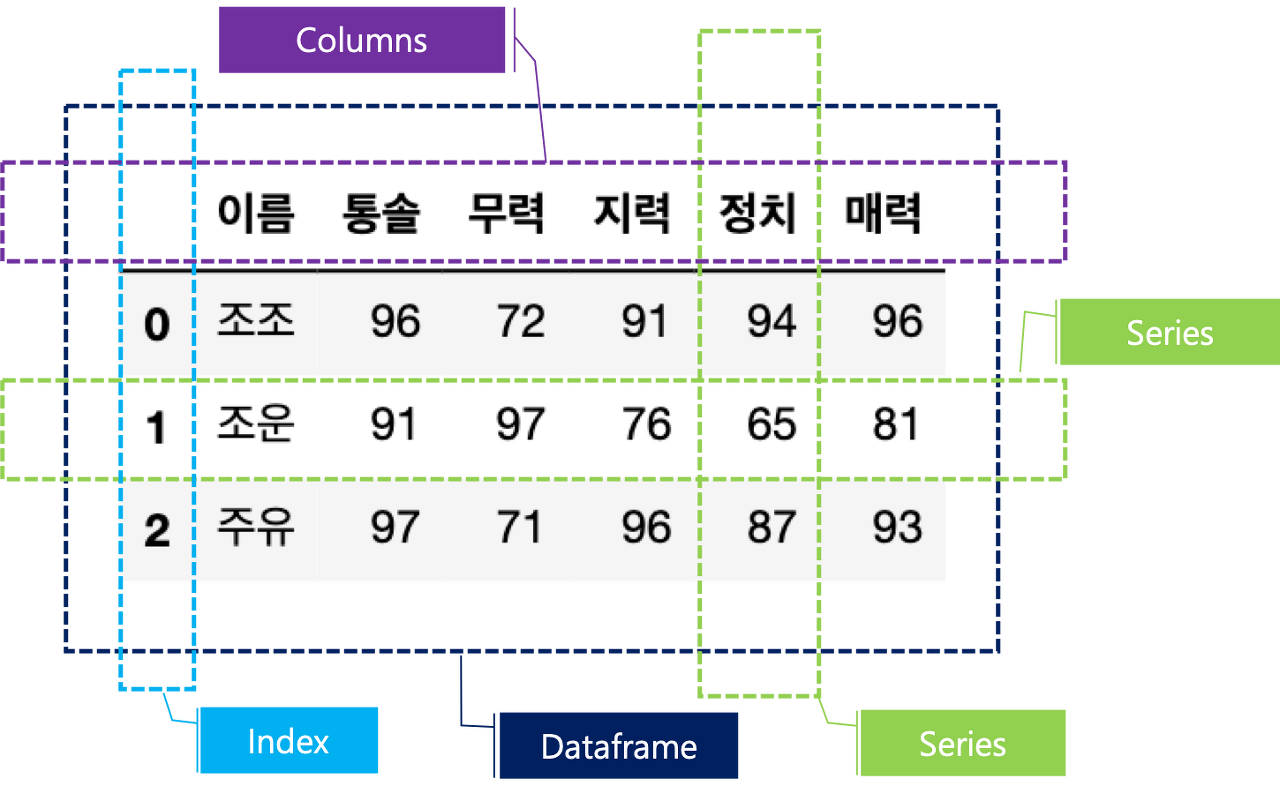
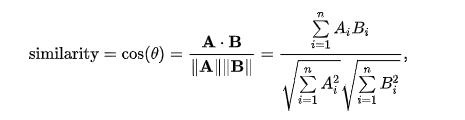normalization Integrate different words to make them the same word-such as US is same as USA integrate them as US. 1. WordNetLemmatizer If words have different forms, find the root word-such as the root of 'am, are, is' is 'be'. from nltk.stem import WordNetLemmatizer lemmatizer=WordNetLemmatizer() words=[ 'have', 'going', 'loves', 'lives', 'flies', 'dies', 'watched', 'has', 'starting'] print('b..